If you have built search experiences, you know creating a great search experience is a never-ending process: the data to index keeps changing, and the search engines and tools keep evolving. Each year new techniques and new tooling are released – the proof-of-concepts of yesterday become the new norm. Therefore keeping up with the latest news and comparing our approach with others in the field is crucial to provide a world-class search and discovery experience!
We went last week to Berlin as a team of 6 engineers (working on the Core Search Engine, AI features, or Recommendation models) to Haystack EU 23, the European Search Relevance Conference.
New approaches like vector search or image capabilities got the stage light this year. But old tricks are still very relevant: order in searchable attributes, or decompounding some languages keep delivering value and saving you precious development time as you build consumer-grade search.
We share a lot about these through blog posts, but live talks have an undeniable energy that makes you want to share and compare with other experts in the field. We’re already discussing what topics are worth bringing on stage – Let us know if there is anything we do, that you would like us to shed some light on! On that we leave you with a quote from the organizer Charlie Hull: “we are hoping to see an Algolia presentation next year” 🤞
A few words on Haystack
Haystack is a conference run by OpenSource Connections, a Search & AI Consulting company. Alongside their main US conference, this is the third year they have organized a European counterpart to bring together the European side of the Search & Discovery builders.
Over two days, this allowed us to hear talks from search providers explaining their approach and new features; from search users leveraging those technologies to reach their business goals, and from industry actors reflecting on our work practices and Diversity and Inclusion in Search.
We’ve learned a lot over the course of two days, both from the high-quality talks and from the deep conversations that happened between them. It’s energizing to see so much innovation in the field, with basic vector search on the road to becoming a commodity, and query categorization getting a place of honor.
In this recap, we share some technical insights we got from the speakers. It was two days packed with talks, and as a team of 6, we covered quite some ground.
If you don’t feel like reading all the recaps, here are our highlights:
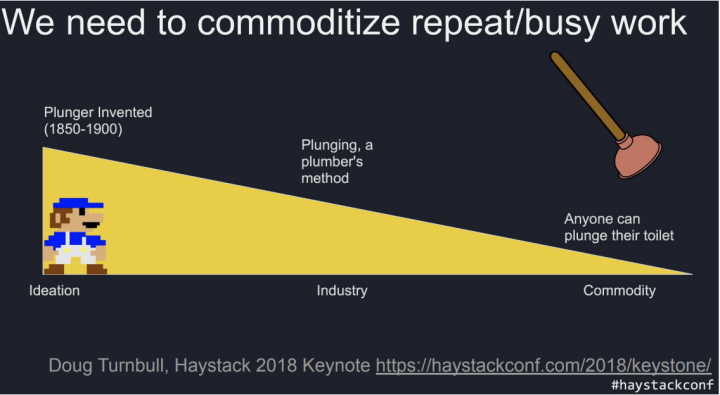
The conference opened with a Keynote by René Kriegler from OSC, building upon their 2018 seminal keynote to contrast the progress over the last 5 years. He showed that search technology is moving up the hype cycle: the previous focus areas (click modeling, evaluation tooling, LearningToRank) are the new commodities, while the hype/research areas (AI, Query categorization, Summarization) are the new differentiators.
More than ever, UX is king: when to use a new tech, e.g. generative AI, often really boils down to UX considerations.
This is where sharing tricks, successes, and lessons from failures is valuable: instead of reinventing the wheel, we can share a common basis and focus on the specifics of the experiences we want to build!
As Charlie Hull puts it, “Let’s be jugglers, not magicians!” : if we share techniques instead of guarding them like magic tricks, we will all benefit from an uplift, do more enjoyable work, and bring amazing search experiences to the world.
How my team moved Search from the #1 to #7 challenge to solve, without changing relevance [Front]
In this talk, Stéphane Renault (former colleague 👋) gave expert feedback on leading a search revamp project. How do you find the right problem to solve? How do you validate the impact of your work?
Using Qualitative & Quantitative methods to understand users, Stéphane shared their strategy from Ideation through Experimentation to Gathering Learnings, with key takeaways about what makes a great experimentation framework.
Key advice was leveraging the RICE methodology to prioritize features; then rallying stakeholders to get support working on priority topics, and tracking negative impacts: some successful searches will result in no interaction (e.g. you found the info you needed, so you close the tool). This means no reliable positive signals -> let’s dig into the negative ones and learn from them instead.
Reciprocal Rank Fusion (RRF) or How to Stop Worrying about Boosting [Elastic]
Have you ever normalized scores? Those who had to, can never forget. Boosting is more of an art than a science, and when your data changes, you’re in for a new ride. According to the Lucene docs, here’s the lesson learned: “Seriously. Stop trying to think about your problem this way, it’s not going to end well.”.
In this talk, Philipp Krenn from Elastic offers an alternative: Reciprocal Rank Fusion, fusing two rankers’ output, in an easy-to-compute way that requires no tuning.
The most simple version of RRF is 1 / item's position. We can make this more flexible by weighing each ranker differently, which brings a new challenge: how do you select the right weight for each ranker?
Philipp shared an early implementation of RRF in Elastic: it doesn’t yet support weights, its main objective currently is to blend keyword and vector results.
This solves most, although not all, problems of boosting – yet doesn’t enable strategies like tie-breaking ranking, which for many use cases are just what you need.
Finally, some hope for making vector search results as understandable as is keyword search: Transparency is still possible with hybrid search – you just need proper experimentation tooling!
At the end of the talk, Philipp presented RankQuest, a tool developed by Jilles van Gurp to help you assess how good your search service or API is.
A lovely illustration, as the opening keynote suggested, of open-sourcing tooling for the greater good.
Break, Learn, Refine – The Art of Hypothesis-Driven Development of ML-Powered Search [Uzum Market]
Running ML projects is quite close to academic research: value comes from trying many hypotheses and validating them efficiently.
How can one link the impact of your search/AI to your business metrics?
Why do some queries have higher returns for business than others?
This is especially challenging for marketplaces, like Uzum Market, where sellers and buyers have different needs. Moreover, search is a core feature of a marketplace, so this is business critical for them.
Andrey Kulagin presented their framework to solve these: To learn the answers, you need to become efficient at running experiments.
There are many offline metrics out there (nDCG@k, MAP@k, MRR, ERR, and even the newly released CTO@k 😛). By correlating these with your business KPIs, you can learn which ones make sense to validate each experiment!
To summarize the insights in this talk, being Hypothesis-Driven in our ML research means testing many directions, finding the right metrics to validate them fast, and accepting failure: it’s an integral part of the journey, and failure is valuable as long as you extract knowledge from it!
Shedding Light on Positional Bias: Strategies for Mitigation [Delivery Hero]
When I’m hungry, I always pick the first restaurant I see. Delivery Hero users too, and that skews their metrics.
You might not know Delivery Hero’s name, but it probably already fed you some good food
So how do you mitigate your user’s bias in your historical interactions data? Especially when you have hungry users? Burak Isikli from DeliveryHero shared some tips to account for that.
A simple first step to remove some bias from metrics is to exclude the first result (getting 10x more clicks), e.g. using nDCG@2-10.
Also, “You can’t measure what you don’t know, but you can still try to predict it”: Learn to estimate the interactions an item would have gotten at a given rank. Train a model to learn the estimation of clicks (interactions/events) an item would have gotten for a given position. Use the model output to evaluate hypotheses. Here position as a feature may result in some overfitting, which you can solve with dropout.
Interesting mention of Punished interactions features (weighting events so that the higher is an item ranked the less an event counts in the training, akin to Inverse Propensity Weighting), or learning an unbiased ranker as in this paper or that simplification (which is already available in xgboost!)
Beyond the known: exploratory and diversity search with vector embeddings [Qdrant]
In this talk, Kacper Łukawski from Qdrant explained clever ways to add some diversity to your search results.
The core idea is dissimilarity search approaches: when adding a different item for serendipity, prefer Diversity search over random samples. To that end, retrieve a wide pool of documents, and add to the resultset the most similar documents to the query and most dissimilarto the documents already in the result set.
This comes at a cost: diversity search significantly increases the number of vector comparisons to perform (wider fetch and dissimilarity comparison). This brought us to a common problem in the field today: how to scale vectors for performance on big datasets.
Qdrant here is looking at binary quantization as a solution. This is a fine approach as in recommenders, centroids can represent user preferences: see why it’s okay to average embeddings.
Finally, Kacper had good advice on vector search distance metrics: know your model, for the right distance is often the one the model’s error was computed with.
Multilingual Search Support in European E-commerce: A Journey with Apache Lucene [Adelean]
In this hands-on session, Lucian Precup from Adelean showed us how to improve multilingual support in the Lucene engine. This is always a hard problem with a lot of exceptions per language to support, and all those customizations build up over time.
Here having a tool/process to manage it (adding vocabulary, exceptions around lemmatization, stemming) is key to scaling your language support.
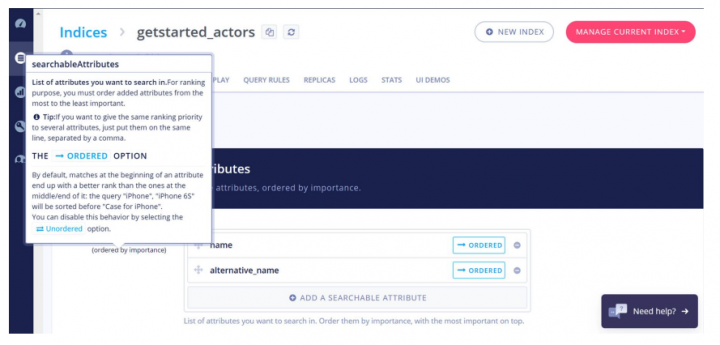
It was nice to see our engine mentioned in a concrete example where semantics can be touchy: take for example the queries “jus d’orange” and “orange à jus”, where the most important word changes – how can you weight the query words accordingly?
Lucian suggested a solution for Latin languages: leverage Algolia for ordered word importance!
This is a pretty old dashboard screenshot – our users have benefited from this feature for quite some years 😁
With the Lucene engine, this requires custom development, which was implemented here by the Adelean team for Latin languages!
Navigating Neural Search: Avoiding Common Pitfalls [Vespa]
The next talk by Jo Kristian Bergum from Vespa mentioned various challenges of neural search.
Indeed, vector search alone cannot solve all search problems. It was said that “vector search doesn’t fix typing mistakes”, which is very true – we have to find an alternative solution, like our approach in NeuralSearch where keyword and vector search results are blended, or e.g. sending subqueries with misspelled word alternatives to the vector engine.
Here, the Vespa team chose to use a Language Model and Approximate Nearest Neighbor.
They used a bi-encoder, which they see as more efficient than cross-encoder as it can be parallelized. A warning on LM size: it heavily impacts performance, so you need to be clear on the accuracy/speed tradeoff.
The ANN retrieval avoids a costly 1:1 comparison with the whole space of documents (see their work on LADR).
A drawback though: the ANN representation space cannot be updated and requires full reindexing; this might bring issues reflecting data freshness and relies on good indexing performance.
A final insight from this talk was a word of caution on the difference between theory and practice: Semantic search doesn’t do a lot of things, so you need to be very careful when implementing semantic search.
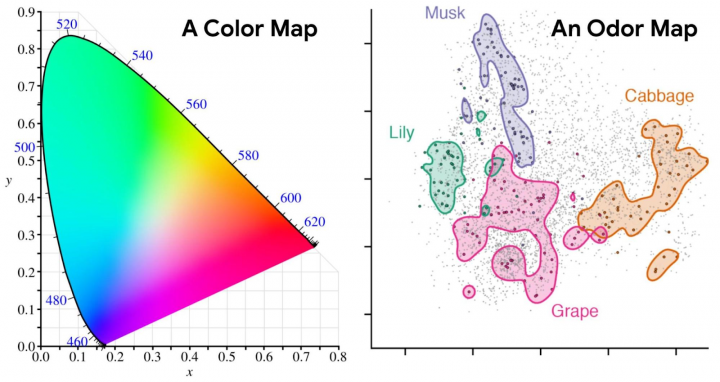
They concluded with a stellar parallel between vector similarity and image similarity:
You might look at a vector model and think “Oh the performance on paper looks amazing”, and yet be disappointed when it runs on your real-life production data. This is a good word of caution: Generic models should be used carefully and must be adapted to your data.
Using Vector Databases to Scale Multimodal Embeddings, Retrieval and Generation [Weaviate]
Zain Hasan’s talk started with a joke about ChatGPT being actually dumber than most of us: “If you think playing chess well is hard, just try making coffee.” Language models might get somewhere in board games, but the ability from these intelligences to make a basic human task (find how to make coffee in a random regular house) is abysmal.
This is Moravec’s paradox: some mundane things are insanely hard for AIs. This can be explained by the diversity of information the human brain receives when learning (audio, taste, smell, reading…). One can wonder if it’s possible to have models learn from different signals to improve the learning process.
So the current breed of artificial intelligence pretty much struggles with anything beyond text today.
But not tomorrow! Multimodality is on the rise. First images, then audio, now video, sensors, time-series, proprioception, even digitized smell – anything goes.
Each modality has its strengths: more allows you to uniquely identifywhat your customers like. Also enables us to compare relevance between items, or identify differences.
Once you’re a multimodal shop, you should explain the contributions of each modality: you can use SHAP values (e.g. via MM-SHAP) to make clear which modality brings what, and help your customer grasp that you’re not recommending those socks based on smell.
Likewise, if you go multimodal and use generative AI, remember such models don’t know what they don’t know. You probably don’t want them to illustrate what that ‘0.52% celery-smelling burger’ might look like, unless you’re at peace with getting an illustration so random it might look like a cosmic horror!
In their talk, Zain proposes to train one model per data and unify them to build multimodal experiences. They use a loss function optimized to “group” similar data points on one side and group dissimilar data points on the other.
Multimodal experiences are exciting, yet we still need to find the killer application: unfortunately, so far we have seen nice demos but no concrete results or benchmarks showing improvements on real life use cases.
Maybe this will come after the work in progress on a unified vector space: a goal hard to get, but which would unlock a lot of possibilities: e.g. we could build experiences where user queries can be multimodal too!
Women of Search
In this excellent, big-picture talk, Atita Arora from OpenSource Connections took a step back from the tech to focus on our human side.
Why do we still lack women in numbers? Why do they report worse working conditions, less trust, lower compensation, and less freedom to speak than their male counterparts?
Atita knows this well – she’s part of a group called Women of Search, bringing together women working in the field of computational search. This offers a platform to understand the challenges that women face in this field; to promote their successes, and to share their experiences.
With a case study of Prefixbox, presented by Paige Tyrrell & Istvan Simon, we could get some insights: filtering for seniority amounts to filtering for overrepresented, providing a career path for people starting in tech is key to diversity (gender, age, country, any kind really), and recognizing achievements & offering help/mentors to juniors is key to retention.
To promote equality, actions must be aligned with reality. They advised to start with the rule of 1: aim at having a person from the underrepresented group in each team. True, being the only representative of a minority in a team can lead to biases; however they noticed that once you add a first woman to a given team, it becomes easier to hire more – so this first step enables many more!
Looking at our own teams, Guided Relevance is pretty diverse; on the other hand, my own Algolia Recommend team has women on the ML engineering side, but not in our Platform team – if you’re passionate about building powerful features and shipping them to a global scale, we’re hiring 🤗
Strategies for using alternative queries to mitigate zero results and their application to online marketplaces [Wallapop]
With René Kriegler from OSC, Jean Silva from Wallapop presented some tricks you can apply to avoid the dreaded zero-results page.
They covered regular usual query relaxation techniques (synonyms, spellcheck, etc.), then focused on generating alternative queries: how to pick the term to drop? They presented results from a very scientific approach, trying and evaluating various methods:
better text analysis (better stemming for example)
Use synonyms and hyponyms
Correct spelling
Loosen boolean constraint (AND ⇒ OR)
Use hypernyms (ex: boots → shoes)
Relax the query (ex: iphone 13 → iphone)
Drop the shortest non-alphabetical term (ex: iphone 14 → iphone)
Drop the least frequent term
Keep the most similar query from variants using text embeddings!
They also touched on UX considerations, tying back to the Keynote idea that UX is king: query relaxation is better understood by users when you make them interactive, e.g. with suggestions that the user can tap on.
In the end of the talk, they advised that Semantic search is sometimes overkill: simple techniques like query relaxing via removing words can cover a lot of grounds for queries with no results. This is basically removeWordsIfNoResults, which leads us to a discussion on behavior: when should you favor the most common word vs. the least common one?
Mastering Hybrid Search: Blending Classic Ranking Functions with Vector Search for Superior Search Relevance [Hyperspace]
HyperSpace wants you to have your cake and eat it too: both benefit from ElasticSearch’s versatility, leverage vector search solutions, and still get the performance you need for a consumer-grade search experience.
Hybrid search is challenging, as you need to balance two very different kinds of engines:
Keyword search has strengths (no AI expertise, works well, structured data)
Vector has strengths: semantic, versatile, easily personalized
Challenges of connecting both include precision (e.g. in healthcare applications, returning a ‘similar’ medication is dangerous – you want precision over recall here, better return no results than the wrong drug), explainability, hallucinations (when you always get topK results, how do you ensure relevance?), and of course scalability.
Their solution is to build a hybrid engine with some in-house built chip: they accelerate key elastic functions like BM25, resulting in a 50x performance boost on these computations.
There was an interesting discussion of pre vs. post filtering: do you filter before ANN retrieval or after? Here HNSW filtering while traversing the graph might be a good middle-ground.
It’s nice to see real-world applications of ASICs-like, special-purpose processing units!
Search Engines: Combining Inverted and ANN Indexes for Scale [Rockset]
This talk by Anubhav Bindlish from Rockset shared a simple, clever idea: combining both the vector search and metadata search in the same engine (RocksDB in this case) so that you have less tech to maintain, where the indexes search are built through FAISS which then also pushes the vector index to RocksDB.
With this architecture, the challenge is addition and deletion. Inserting is costly and inaccurate, and you need to rebuild your index after a number of updates (which takes ~100ms). The CPU contention prevents real-time: they mitigated this challenge with Compute-Compute separation, sharing only the data.
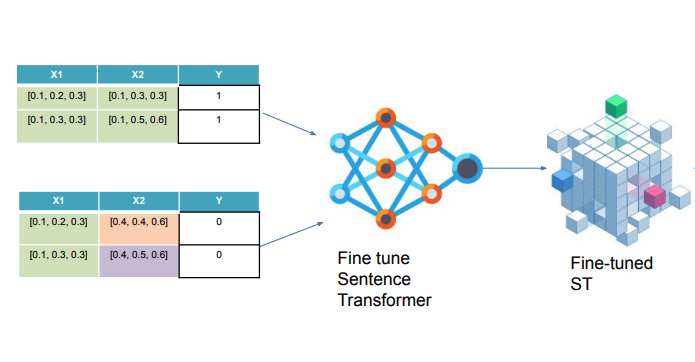
A Practical Approach for Few Shot Learning with SetFit for Scaling Up Search and Relevance Ranking on a Large Text Database [N2VEC]
N2Vec is a search engine for Enterprise Documents. In this talk, Fernando Vieira da Silva presented how Data is the main challenge when training such a model for lowly structured use cases.
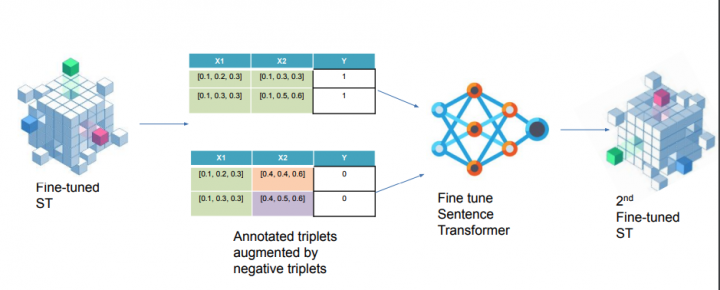
They propose a model to generate some training data based on few shot learning: SetFit – Sentence Transformer Fine Tuning to work with data without labels.
They then fine-tune it a second time using triplets of positive/negative examples!
This seemed quite complex at first glance, but this idea of iterative fine-tuning might be just what you need for some applications where you want both ease of training on unlabeled data and yet get some reinforcement of what human annotators will label as good or bad results.
Evaluating embedding based retrieval beyond historical search results [eBay]
In this straight-to-the-point talk, Yu Cao from eBay presented how query & item embeddings can be evaluated against your actual business goals.
Yu argued that you want to check embeddings on three aspects: that the query embeddings behave well, that the item embeddings are well-behaving too, and that bothcooperate efficiently:
If two queries bring similar items, they should be embedded close
If two queries embed close, they should retrieve closely embedded items
In reality, we don’t always see such nice results – yet this is a good criterion to evaluate your system upon.
The conference ended with various lightning talks. Among many, we particularly enjoyed:
Using FPGA for implementing search to speed up elastic computation, from Hyperspace
Roman Grebennikov’s witty talk on horrors of relevance tuning: here Roman shared fun battle stories about bad textual embeddings. He argues how embeddings are generated matters more than how they are served, hence changing the retrieval technology cannot help when the underlying embeddings are bad.
A talk by TomTom on using language models in their GPS products: here they advised us to keep in mind that even though you can use a language model you don’t necessarily need one. You might find alternatives that are simpler, cheaper and have a lower carbon footprint.
Conclusion
Haystack23 was a very insightful conference. We saw many different actors coming together to explain their approach to traditional search and beyond, their efforts on making vector search scalable, or on offering image understanding capabilities.
Huge thank you to all the speakers who had great content to share, to the attendees for the deep conversations around the talks, and to the OSC organizers for the flawless organization! See you next year 👋
Team:Hugo Rybinski, Claire Helme-Guizon, Sarah Le Moigne, Sriharsha Chillara, Vincent Camus, Paul-Louis Nech