Most of world’s languages feature a wide range of unique quirks that make search engines stumble when processing queries. In this article, we’ll present features we implemented to solve these issues, and go over their rationale and technical implementations.
Our engine is language agnostic, which means it’s designed to work with every written language. This is no easy feat, considering all the little and big differences languages have, from being based on symbols from different alphabets like Japanese or using many variants of the same stem like in German.
There is no silver-bullet or magical way to handle each of these specificities. Some of the most common approaches rely on statistical models, which are by default close to impossible to debug and iterate upon. Our goal was to design a system that is not only simple to iterate upon, but runs fast and works transparently.
We believe that we’ve found ways to achieve a great relevance in many of the world’s languages. Today, we’re explaining our approach, and how to best use it to configure the relevance of your Algolia index for every language.
Normalizing characters
A well known low-level step while doing NLP is normalization. The goal of this step is to depend more on the letter than on the way it was typed, to reduce friction between what the user wants and what has been indexed in the first place.
This step is actually composed of two steps:
Using the Unicode standard and Unicode supplements to find the canonical form of the letter: À → A or ß -> ss, for example. For additional detail on how we handle Unicode, you can refer to this post.
Using the Unicode standard to find the lowercase form of the canonical form: À → A → a.
Those two steps are applied on the text while being indexed, and on the query, when a search is performed.
The normalization into lower case characters is easier to grasp: requiring an exact capitalization of the query is too strict to allow for a pleasant search experience.
Lately, however, we have been questioning our strategy of indiscriminately removing the diacritics (´, ¸, ¨, etc.).
The strategy was designed for the languages we started with — including the French — and it brought a couple of benefits:
Be resilient to missing/extra diacritics when users are typing on mobile.
Allow users that can’t or don’t know how to type some characters to still be able to search for them.
However, our bias led to some languages being harmed by this mandatory step of our search engine: mostly Nordic languages (Swedish, Norwegian, etc.) and Turkish. In French, e and é are considered by native speaker as more or less the same letter; for a Norwegian speaker, o and ø are not interchangeable at all.
Interchanging two such letters can create an issue by making the search unable to discern between two completely different words, like in this example in Turkish: cam → glass, çam → pine (pretty annoying if you are focused on selling furniture).
As we already mentioned, this step is today mandatory in Algolia’s search engine and can’t be disabled. We are thinking on improving this to allow a more granular handling of languages for which diacritics play an important role.
Typo tolerance
Typo tolerance is an important part of a search engine, and one of the earliest features Algolia brought to the table. Its role is really simple: be resilient to input mistakes, or plain misspelling.
The rules for the typo tolerance are as follows:
if a letter is missing in a word, we consider it a typo: “hllo” → “hello”
if there is a extraneous letter, we consider it a typo: “heello” → “hello”
if two consecutive letters are inverted, we consider it a typo: “hlelo” → “hello”
By default, Algolia accepts 1 typo for words that are at least 4 letters long, and 2 typos for words that are at least 8 letters long. Those thresholds are configurable by the user.
On top of those rules, we added some subtleties, such as the fact that a typo on the first letter of a word is “penalized” double, because it is much less common to mistype the first letter of a word than any other letter.
Those rules are easily applied to languages using Latin alphabets: while some languages tend to have shorter or longer words on average (which could be translated to increasing or decreasing the minimum number of letters before accepting typos), they are all similar in the way typo tolerance can be configured.
Languages using logograms, such as Chinese or Japanese are, however, a whole different story. Because of the way those languages are input, the typos as we know them in Latin alphabet languages don’t really occur.
However, those languages are subject to the presence of alternative logograms for the same word. Those alternatives can exist for two reasons:
the presence of a traditional and a simplified drawing for the same character
the presence of two logograms that can be used interchangeably
Removing stop words
In the last couple of decades, while browsing the internet, most of us adopted the habit of transforming natural language questions such as: “What is the best search engine?” to full-text queries we knew would be better interpreted by search engines, such as: “best search engine”. While those requests used to yield better results thanks to the decrease of noise in the query, this is less and less true because of two major factors:
Search engines adapted to allow more casual users to find their results without having to pick up this habit
The advent of voice search is favoring the use of fully formed sentences
By default, Algolia is requiring all the words in the query to be present in a record for it to be considered a match. While it is possible to remove words when no results are found, all the words will still be considered equal, and “the” won’t be considered as less important than “search”.
To handle this case, we introduced pretty early a removeStopWords setting that removes all the “unnecessary” words from the query string, and eventually keeps only “best search engine”.
To accomplish this, we are using a really simple dictionary-based approach. We parsed several sources (Wiktionary and ranks.nl) in order to constitute a list of words commonly used as stop words, not only in English, but in ~50 languages available.
The first implementation of the setting was suffering from a major flaw: it was a single boolean value, and one could only activate this feature for all languages simultaneously or not at all. A lot of corner cases were observed: like “thé” (the French word for “tea”) being removed because of “the” being an English stop word, thus transforming a really specialised “magasin de thé” (tea shop) into a regular “Magasin” (shop).
Since then, we changed the setting; the feature can now be set to a list of languages, allowing one to remove stop words from one language at a time.
While this feature doesn’t work well in itself with languages not using spaces (such as Japanese), once coupled with other pre-processing steps (such as word segmentation) it behaves just the way you would expect it to.
While the list of stop words for a given language is not likely to change, we still have a few ideas in mind in order to improve this feature:
Add support for more languages
Introduce an option to make those stop words optional; meaning that they won’t prevent results from showing but will influence the ranking if they are inside a record. As of today, they are simply removed from the query.
Handling alternative forms
In English, words have a rather limited number of alternative forms:
nouns have a plural
verbs have a few conjugated forms
However, even if “car” and “cars” are not so different from each other, there are use cases where you still want to consider them as one and the same (“feet massage” and “foot massage”).
To tackle this issue we created a parameter called ignorePlurals which has over the years undergone several transformations.
The problem can be solved in two different fashions:
1. When indexing words, strip them to their singular form: “feet” → “foot”, “massages” → “massage”. Whenever a query is sent, do the same to each words of the query: “feet massages” → “foot massage”, then search for those radical forms.
2. Index the words the way they are given (“feet” → “feet”), but generate all possible alternatives for all the words in the query: “feet massages” → “(foot|feet) (massage|massages)“ and search for any of these forms.
At Algolia we chose to go for the second method. The reason is simple: typo tolerance. If the word is not indexed exactly as it was given, then you can’t accurately compute the number of typos afterwards: that’s why it is important for us to not alter the words that are indexed.
There are two Natural Language Processing (NLP) techniques to reduce a word to its singular form or find its alternative forms: Stemming and Lemmatization.
Stemming is relying on rules such as: if your word is ending with “ing”, strip it. The most popular implementation of stemming is called Snowball.
We have mixed feeling towards stemming, as a single rule could cause a lot of harm if you consider the following points:
Different languages could be present in a single index, meaning that English stemming rules could be applied to French text, which is likely to create a ton of non-valid words, and yield to noisy, confusing results.
Several of our use cases make heavy use of brand names, proper nouns, street addresses, etc., and for those, using arbitrary rules designed for common nouns degrades a lot of the relevance
Lemmatization, on the contrary, doesn’t try to create general rules, and relies on a dictionary giving for each word its radical : “eating” → “eat”, “ate” → “eat”, …
We make heavy use of lemmatization. The only thing that lemmatization efficiency depends on is the accuracy and completeness of the dictionary used. We are continually working on improving our dictionary, primarily based on Wiktionary.
Wiktionary relies heavily on templates such as {en-noun|s} allowing Wiktionary contributors to declare alternative forms when writing a page on a word. For example, {en-noun|s}, would show up like this on the “car” page of Wiktionary:
By using those templates found inside the Wiktionary data, we are able to build our dictionary of alternative forms. Almost every language has its own template syntax, and many languages have multiple templates to do so. Because implementing everything at once is extremely tedious, we chose to improve our dictionary gradually, mostly upon user feedback about missing words/languages.
We spent a fair amount of time on this, and improved a lot of the features over time:
As mentioned above, for removeStopWords, the feature started being a simple boolean switch, allowing only an “all-languages-or-nothing” behavior. It is now possible to specify which languages the lemmatization should be used with.
Languages like German also have alternative forms depending on the grammatical role of the word in the sentence. This is not a plural per se, but we have had a customer reaching out to us in order to support this. And so we did! That makes today’s name a bit misleading as it’s not about plural anymore, but also declensions, diminutives, etc.
ignorePlurals evolves a lot: words are constantly added, new types of alternatives are supported (e.g., most recently, Dutch diminutives). The hardest part is actually not adding words, but finding the right balance between improving relevancy and harming it with noise.
Segmenting CJK text
CJK stands for Chinese, Japanese, Korean. The acronym is pretty popular and we use it a tad inaccurately by using it to refer to any language that doesn’t use spaces to separate their words (Thai and Lao, for example).
Finding the words in a query is a capital step of a search engine: when you are searching for something, you want documents containing the words of your query, but not necessarily in the same order. You want the engine to be less strict about whether words are consecutive. For example, if you are searching for “chocolate cookies”, you don’t want only results with “chocolate” and “cookies” back to back — you also want “chocolate chip cookies” and “cookies with chocolate chips” to show up in results.
When a language delimits its words with spaces, things are relatively simple; when it doesn’t, you roughly have 3 choices:
1. Take each character separately. At first, from the point of view of someone not familiar with CJK languages, this makes sense, especially with Chinese or Japanese. Those languages heavily use logograms, and we have the false impression that 1 character = 1 word. This, however is not the case, as many notions are expressed as logogram compounds: a concatenation of several logograms that make up for a new word. Besides, as mentioned, Chinese and Japanese are not the only ones not using spaces. That leaves this approach out of question.
2. Require the exact query to be inside the matches, verbatim. This greatly constraints the search, but it at least keeps the meaning of the query. While far from being perfect, it’s an acceptable fallback if the method I will introduce next fails. Example: 寿司とラーメン (sushi and ramen). While you would want to be able to also find ラーメンと寿司 (ramen and sushi), with this method we would constraint the results to documents containing only 寿司とラーメン (sushi and ramen).
3. Find by yourself the words inside the query. The segmentation of a sentence into words is a problem CJK experts have always faced, and several satisfactory techniques have been elaborated to solve the issue. None of them guarantee a 100% accuracy, and like everything else in engineering, it’s only a matter of compromise between speed/cost and accuracy/quality. This is the behavior we implemented inside the engine.
There are many ways to implement the segmentation, ranging from statistical to dictionary-based methods.
We strive for an as-you-type experience, which gives us roughly 100ms (threshold below which our brain doesn’t really register difference in speed of response) to answer a query, network latency included. Because of this requirement, we settled for the fastest method in order to find words inside a query: dictionary-based, as implemented in the ICU library, using the MECAB dictionary enriched with data from Wiktionary.
The idea is simple: starting from the left of the query, we will try to decompose the query with words that are present in our dictionary. In case of ambiguity we are prioritizing the solution that maximizes the length of the words and minimizes the number of characters not belonging to a known word.
As of today, we already have a couple of ideas about what we could do to improve the segmentation of CJK languages. First and foremost, the segmentation is based on a dictionary, which means that any improvement made to the dictionary is sure to improve the overall segmentation:
Improving the dictionary means removing words that are extremely rare, as much as adding common ones.
We also heard the feedback from customers about the segmentation underperforming when named entities (such as brand name, people, etc.) are present inside the query. Those entities are not always found inside our dictionary, and the segmentation step is often not able to accurately separate it from the other words. Introducing a custom dictionary that the user herself can improve with custom names is something we are thinking about.
Indexing agglutinated words
There is another issue that is in fact really close to the segmentation of CJK characters. In some languages (German, Dutch, Finnish, etc.) several nouns can be concatenated without space to form new words. For example, Baumhaus is a German word composed of Baum (tree), and Haus (house) which designates a “tree house”.
A person searching for “Baumhaus” (tree house) may very well be interested in results containing something like “Haus in einem Baum” (house in a tree), but the default Algolia behavior is to only search for Baumhaus. This issue is what triggered us to spend some time working on handling agglutinated words, or compounds, better.
The very first step that we implemented was a naive splitting of the words in the query. The idea was simple: in the case of “Baumhaus”, if the index was to contain “Baum Haus” consecutively, a match was possible. This feature was more akin to a typo tolerance on spaces than a real split of compound words, as the words still had to be adjacent to one another, which is a limitation we got rid of in the new version.
Since then, we settled for full fledged processing steps that look individually at each word. If the word happens to be a compound word (we are here again relying on static dictionaries to avoid false positives), its various parts are indexed separately.
As of today, this setting can be activated using the decompoundedAttributes setting. The languages we wish to attempt a decompounding for must be specified; three languages are implemented: Finnish, German and Dutch.
We designed this feature to interact with all the other goodies coming with Algolia: synonyms, ignorePlurals, etc.
This setting is still rather new, and we expect to allocate time improving the dictionaries used by the decomposition process in order to increase the accuracy of the feature. While today we don’t have a strong demand for languages other than those implemented, additional languages may show up in the future.
Automatic concatenation
For languages which use spaces to delimit words, there are still subtleties around separating words, for example with acronyms or words separated by hyphens or single quotes. We will review two cases to better illustrate how Algolia handles this.
Acronyms: D.N.A.. There are two ways of approaching this:
1. considering that we have three words: D and N and A
2. considering that we have a single word: DNA
In this case, the second solution makes more sense:
People may search both with D.N.A. or DNA. Considering it always as DNA makes it searchable whatever its form inside the query or the index.
Algolia uses prefix search if configured to do so, which means that “D N A” as three separate words can match every record that has 1 word starting with D, 1 word starting with N and 1 word starting with A. This is likely to match a lot of results that have nothing to do with DNA.
In this case, we consider D.N.A. the same as DNA.
Compounds: off-campus or a.to_json. If we were to apply the rules previously established for acronyms, we would index and search for offcampus and classmethod. In those cases, this is not the ideal behaviour. In the case of compounds, words can be searched individually, or even written without the punctuation in between: both “off campus” and “off-campus” are valid spellings. Transforming “off-campus” into “offcampus” would prevent a search for “off campus” to retrieve results containing “off-campus”.
In that case, “off-campus” will be considered as “off” “campus” and “offcampus”.
In the case of “a.to_json”, we will consider “ato_json” and “to_json”.
This behavior follows two simple rules:
If letters are separated by separators, consider the concatenation of those letters without the separators in the middle (D.N.A. → DNA)
If each separated component is three or more letters, also consider it as a standalone word (off-campus → off + campus + offcampus).
Those rules allow for enough flexibility on the presence or absence of punctuation, and avoiding unnecessary small words like “a” for “a.to_json” that could hurt any prefix search.
Summary
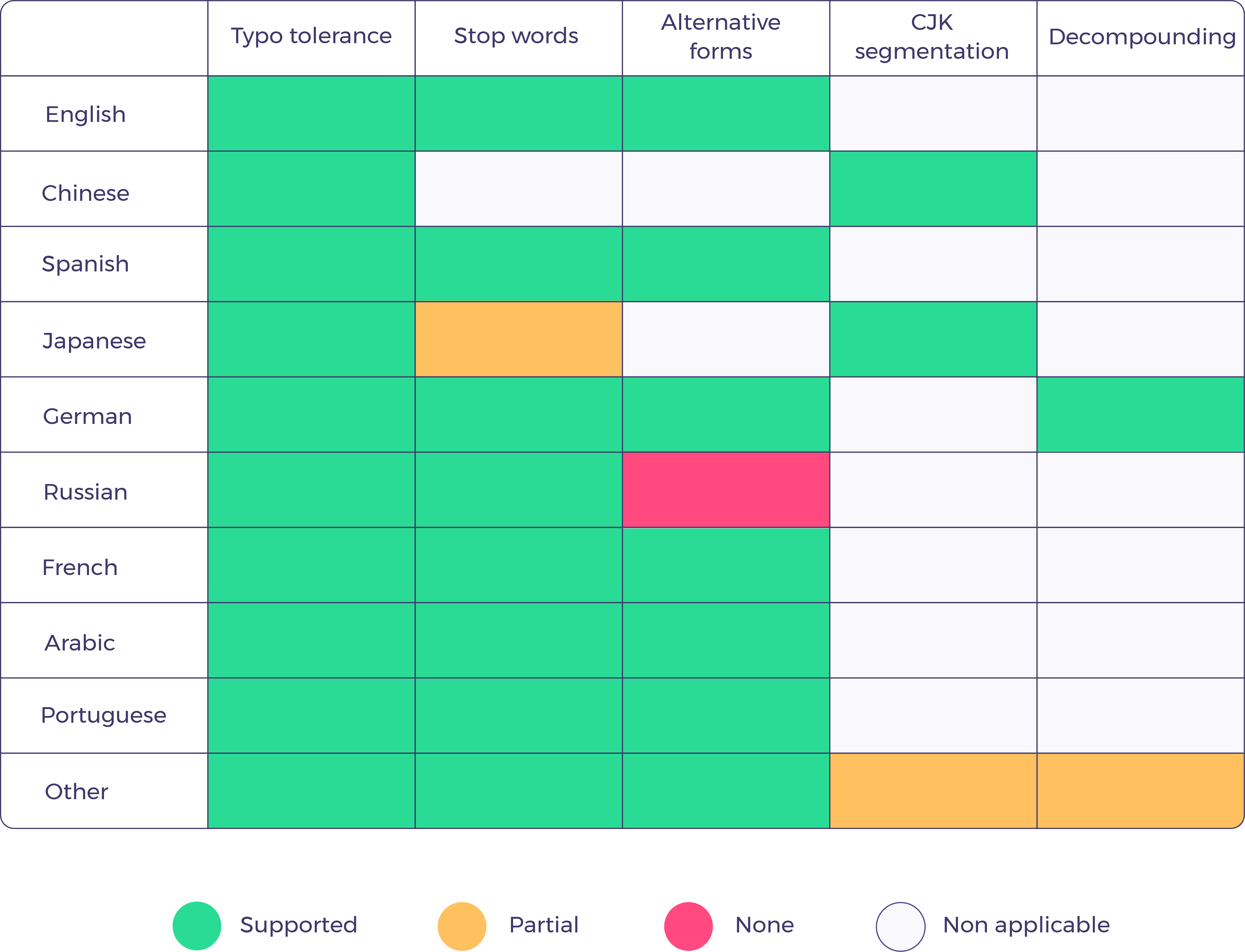
Below is a table roughly summarizing the different pre-processing steps we are applying on some of the most popular languages found across the Internet:
While we are always striving to address languages specificities, we know that we are only at the very beginning of the journey, and we already have a long list of language-related issues we want to address further.
Those issues relate to various parts of the processing of a query:
at the character level: transliteration between hiragana to katakana (two of the three Japanese alphabets) and vice-versa, transliteration between the digits of different languages, better handling of diacritics for languages that suffer from our current method, etc.
at the grammatical level: improving our dictionaries to even better handle stop words, plurals, declensions, and maybe conjugations
at the typo tolerance level: a way to handle the Arabic habit of omitting vowels, a deeper look into languages such as Thai that are different from both Indo-European and CJK languages, etc.
last but not least, sustaining the effort of improving our numerous dictionaries, in order to improve the efficiency of our current processing steps.
If you have ideas or feedback, we’d love to hear it: comment below or tweet to us @algolia.
About the author
Software Engineer
Win personalization with search and discovery
Surface the right things for the right users — without being intrusive.