It was time to migrate our hefty Analytics data to another server. We had been processing the Analytics data on Citus Data’s Citus Cloud on Amazon’s AWS for five years, when we learned that Microsoft acquired Citus Data. We also learned that the Citus startup’s co-founders and team started working on providing a similar service on Microsoft Azure, called HyperScale (Citus). With their help, we decided to migrate our Citus Cloud database to Citus on Azure.
One of the big advantages of migrating at this time was that the Citus team had ownership of both systems, so they would be able to perform parts of the migration process for us.
The data, pipeline, and PostgreSQL
Our real-time Analytics data exists in two different regions: one in the US, one in Europe. To give you some perspective about the migration, those two clusters represent approximately 5TB of data spread over 20 machines.
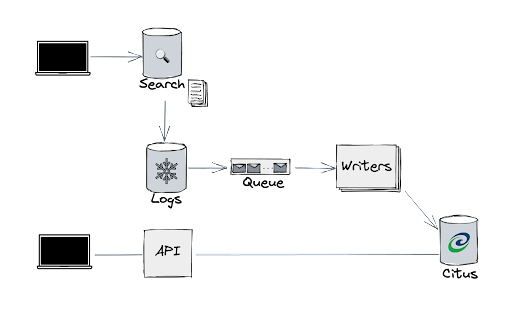
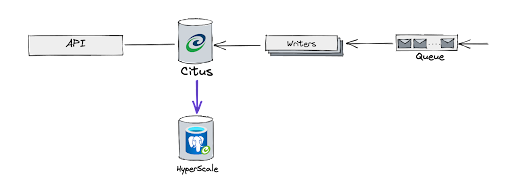
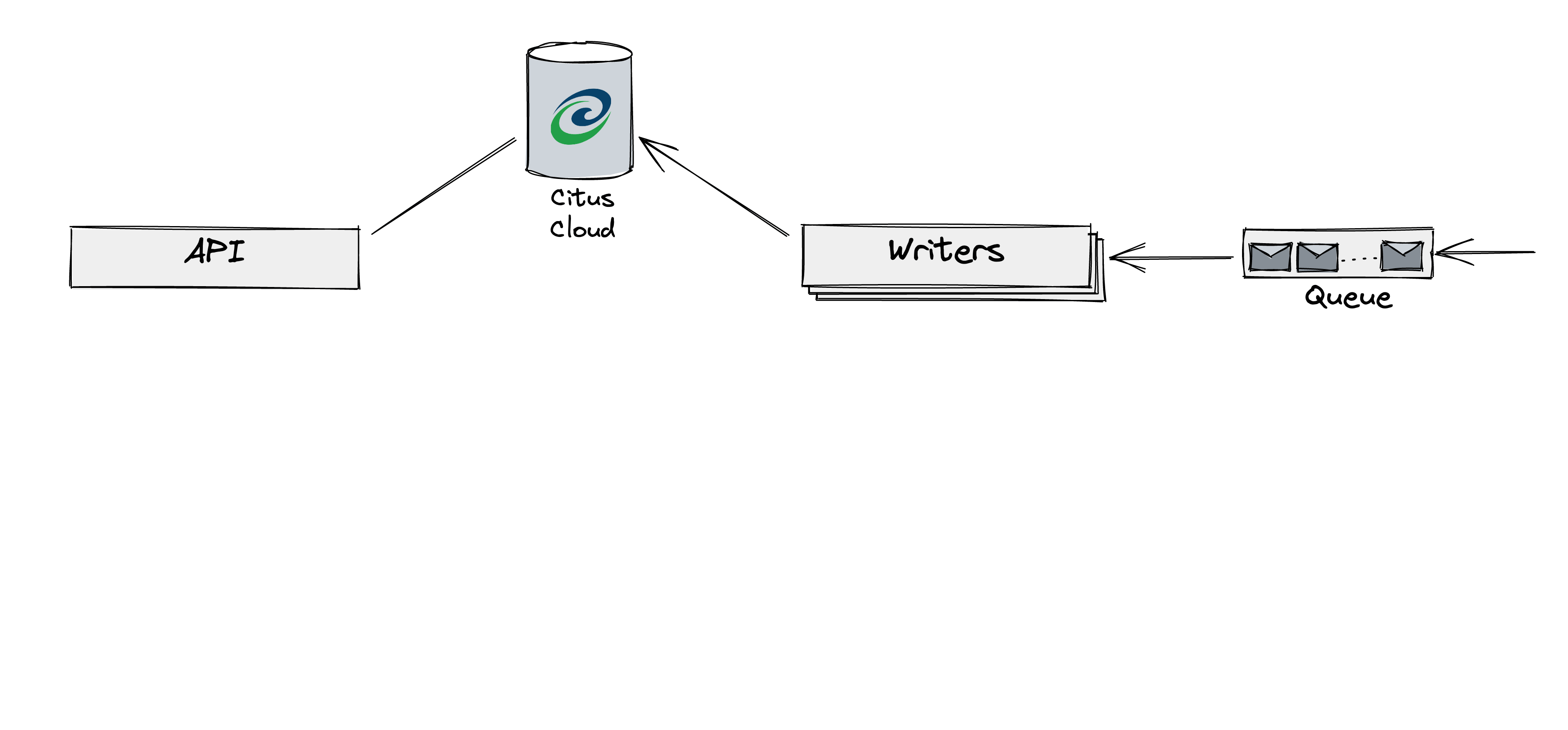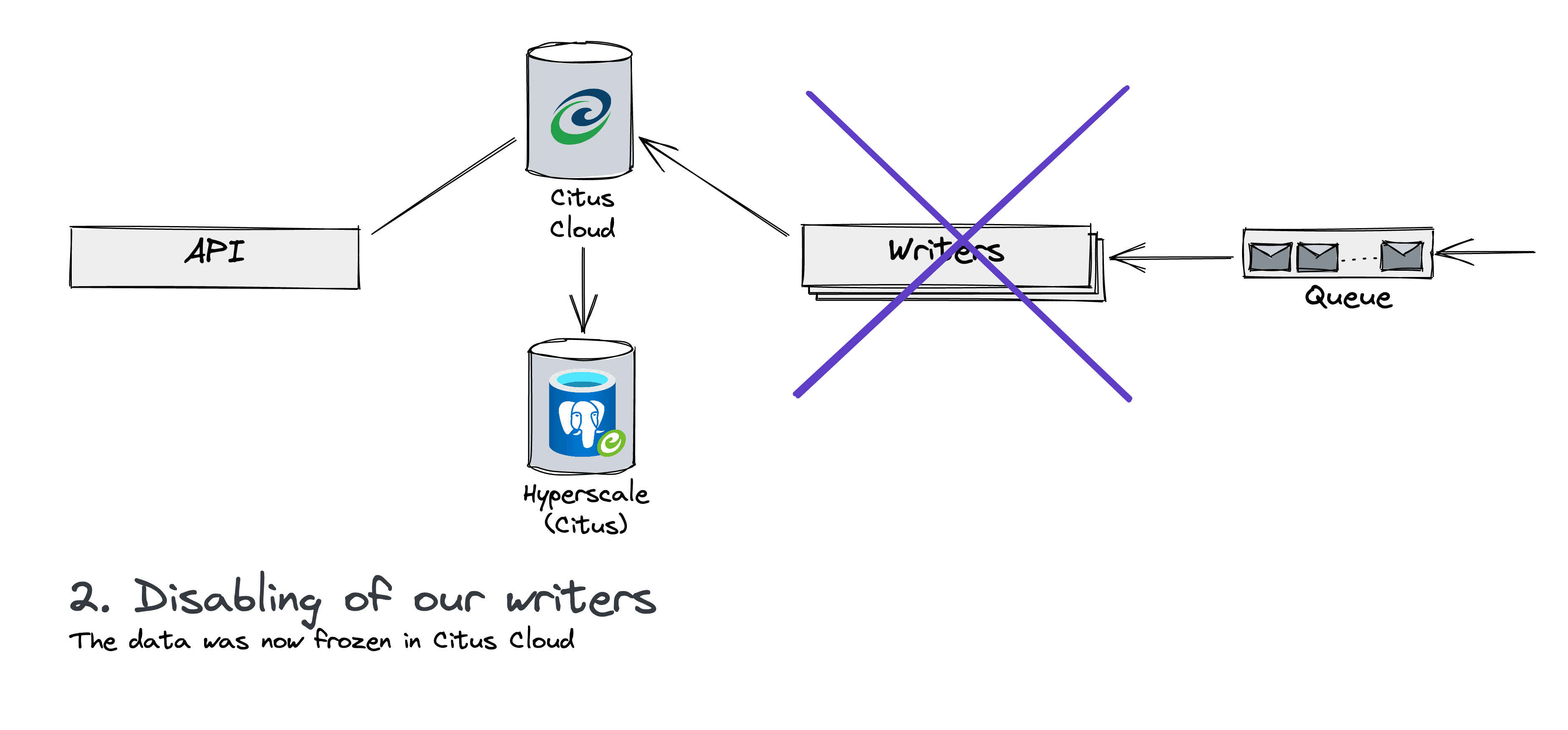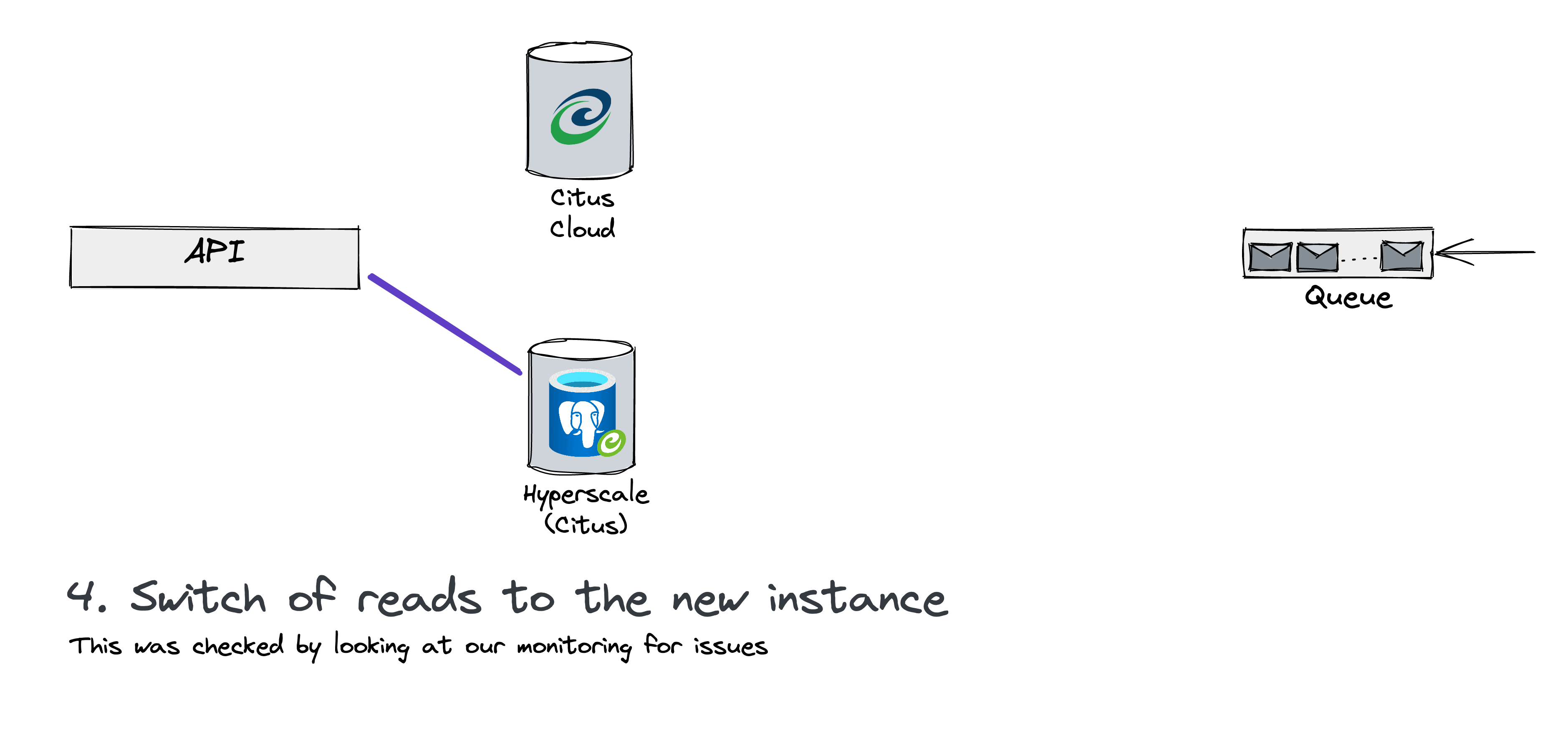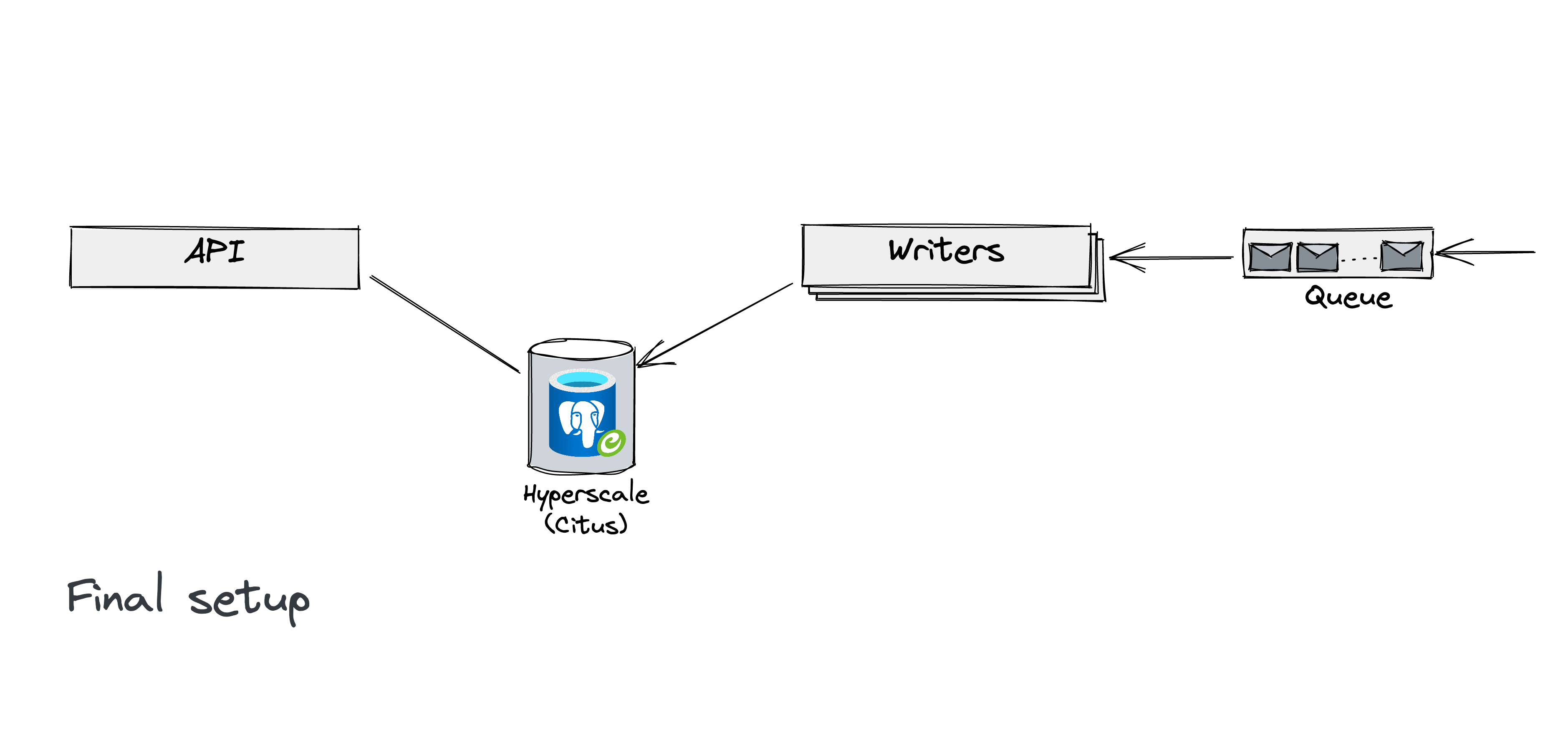
Citus data transforms PostgreSQL into a distributed database. Here’s our Analytics pipeline:
At the top left, a user searches, which generates logs
The logs are aggregated and sent to a remote storage
Whenever the storage receives a new log file, a message is added to the queue
Our writer-workers read those messages and compute aggregates that are stored in our Citus database
The bottom left shows the customer-facing access to the Analytics data via our Analytics APIs. The APIs query our Citus database, performing additional aggregates on top of the aggregates already stored inside the database.
So how did we migrate this data without any downtime?
Upfront constraints: no disruption of services, 100% transparency
We started by defining guidelines and constraints:
Minimal downtime during the migration. Our analytics data is available globally, 24/7. It’s central to our product base and machine learning systems. With Analytics, our customers can scale and continuously improve and configure their solution.
Transparent to the users. We could not disturb the usage. Transparency is not only about no downtime, it’s also about not introducing any performance or services differences or regressions.
No refactoring. We wanted to focus on the infrastructure and data, not on adding any new features or instability into the existing codebase.
No change in pricing. We did not want to add infrastructure costs to our customers under any circumstances.
Plan and design before doing: writing a playbook
Because of these no-service-disruption/transparency constraints, we decided to write down every action we would take before starting the project. We knew from experience that migrating a real-time, distributed big data system is not simply about moving the data onto a different machine and changing connection strings.
The playbook
Comparison analysis:
ensure there were no significant differences between the old and the new systems
Preliminary considerations:
Coordinate actions with suppliers and internal teams (e.g., synchronize with Microsoft and our infrastructure teams to list the actions they would take)
Establish verification steps at multiple stages of the process, to make sure no silent failures went undetected
Plan a recovery procedure that could be used at any point to revert and rollback to our previous instance in case anything went wrong
Migration steps:
Copy the old to the new
Test each piece of the migration process
Perform simulation tests
Test in production
Rollout / Go live
Monitor
For each item in our playbook, we wrote down the actions, tools, and people we needed for each task.
One thing to note. While a playbook should build confidence, it should not create a false sense of security. Every playbook will contain hidden biases and sometimes false assumptions. In our case, the playbook contained an important bias which we will discuss below. Luckily, we detected the bias early in the pre-testing phase.
We’ll discuss two parts of our playbook: the comparative analysis and migration steps.
Comparing the old with the new
To ensure a perfect switch-over, we examined each physical and software layer. We wanted to make sure that the target source would not introduce any different or new element into the current workflow.
Adhering to our constraints, we looked at the following:
Hardware: CPU, RAM, and disk performance
Good news: Azure had comparable machines, everything looked good on this side
Software
Good news: Same Citus & PostgreSQL versions, so we could migrate without having to bump up to any of the major versions
Good news: Microsoft would manage the versioning during the migration process
Infrastructure
Good news: Same SLA
Good news: Same regions available for our servers
Good news: Same security & confidentiality features
One difference we noted was related to the file system. With AWS, we relied on the ZFS file system for its compression capabilities. However, the ZFS file system is not supported in Azure. We checked whether this would be a problem for the migration. Without such compression, we had to keep in mind that we needed more disk space on HyperScale – in our case, 2 to 3 times more.
Thanks to this comparison analysis, we were sure that the new system would not differ from the old in any significant way.
So, with all that upfront design and analysis, we were ready to go.
It’s best to separate the rest of this article into two parts:
Testing strategies
Replication and replacement
Testing strategy: test every link in the chain
Central to testing is to break down a process into its most discrete parts. In our case, the big picture is the read/write breakdown. We wanted to test each of those processes individually.
Performance problems with our write operations
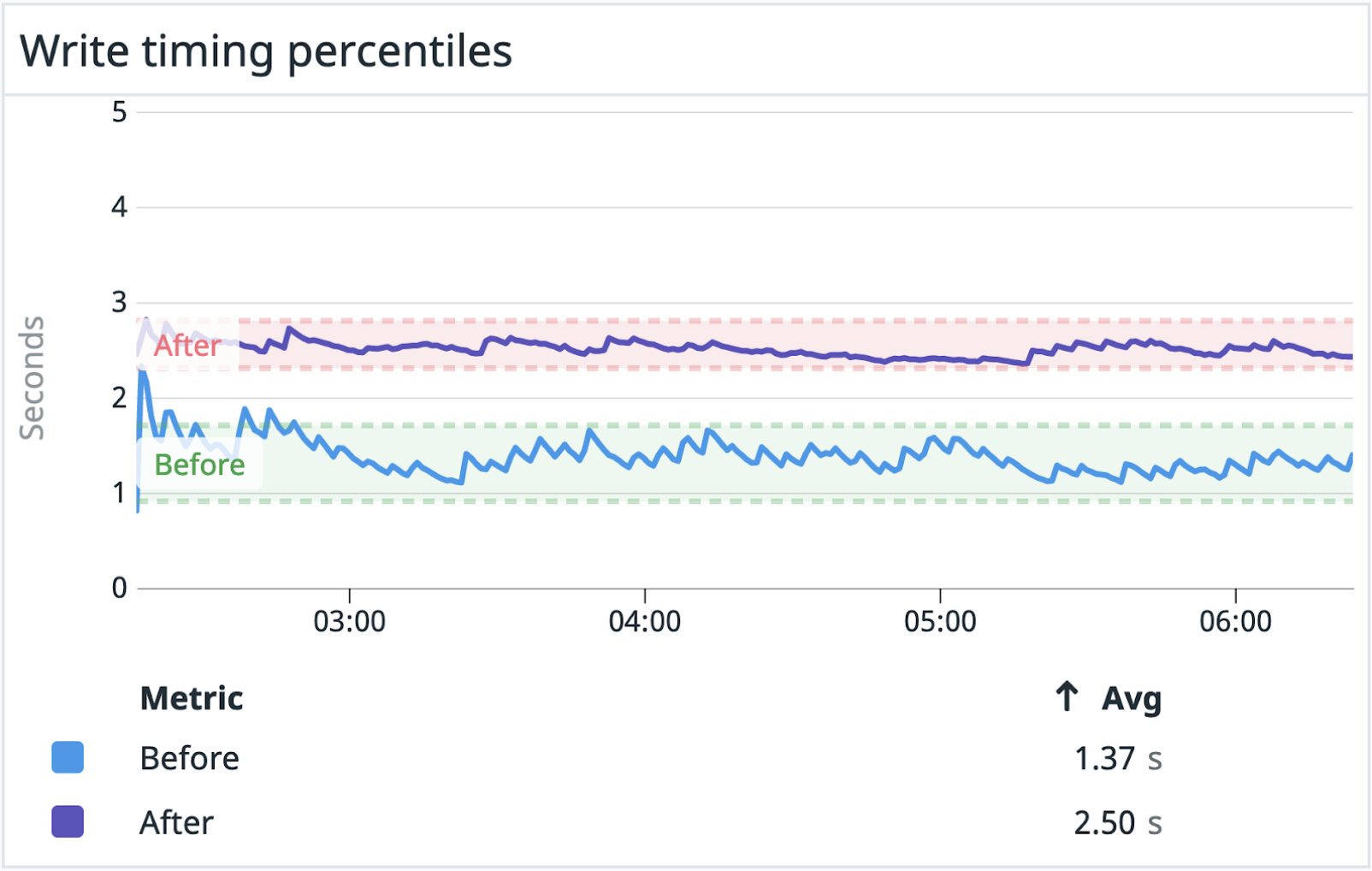
The read operations did not cause any concern – as you’ll see later, there was no regression. On the other hand, we immediately noticed a regression in writing to HyperScale (Citus): it was twice slower and took twice as many resources.
Here we discovered an important bias. We had entered the testing phases mostly concerned about read regression, as our products are known for their speed. But the read part worked perfectly right out of the box. The delays were on the write side – which impacted the end-user experience as well, in both performance and service.
So, here’s where we had to adjust the playbook. We needed to add additional steps and tools to focus on the writing processes. Up to that point, we had tools to examine problems with the read. Now we had to add the following tools to examine the writes:
Audit the `pg_stat_statements` system view, to track the performance of the queries being executed on the database.
SQL query plans, to run the `EXPLAIN ANALYZE` command to compare the old and new performances
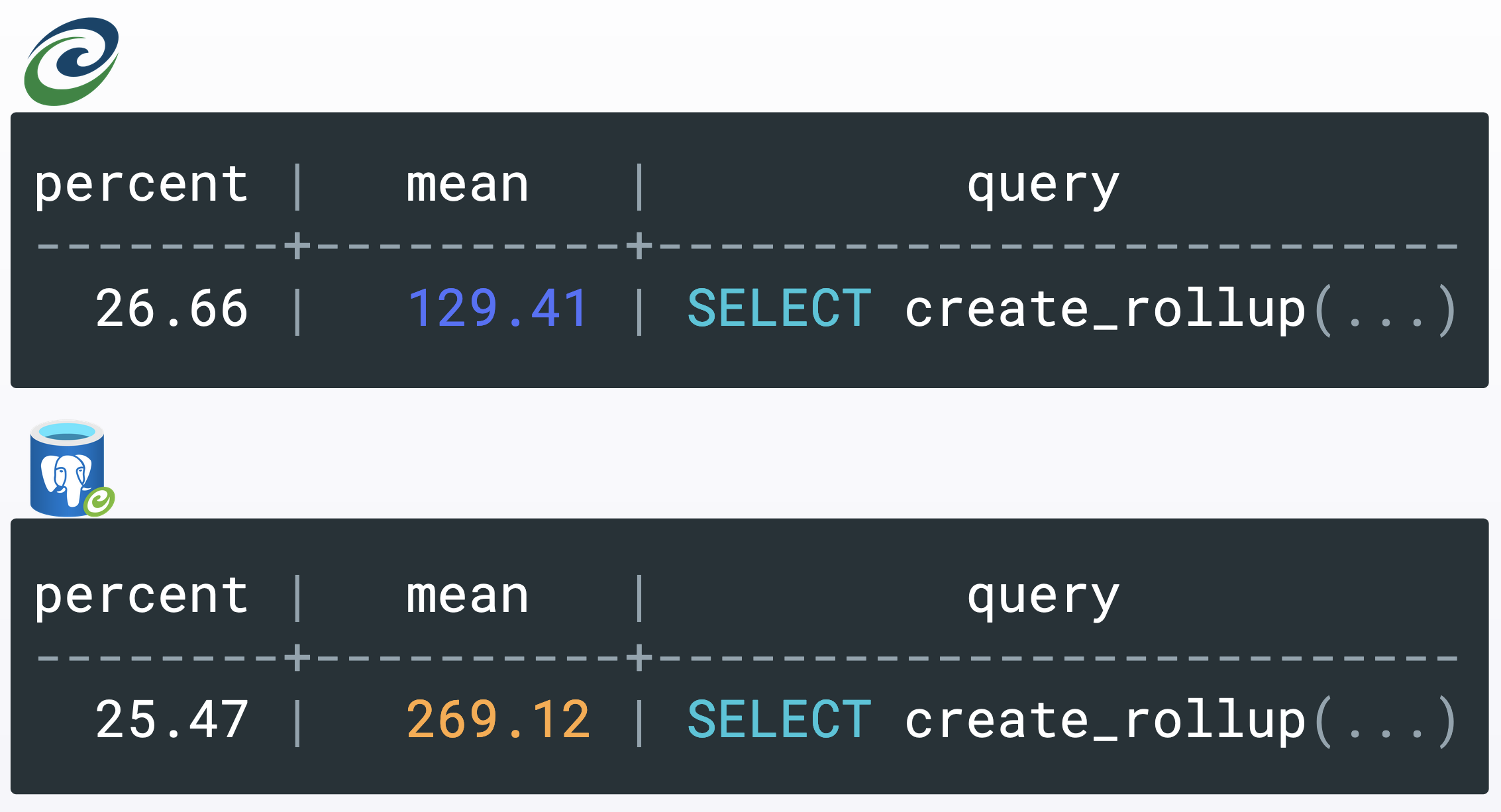
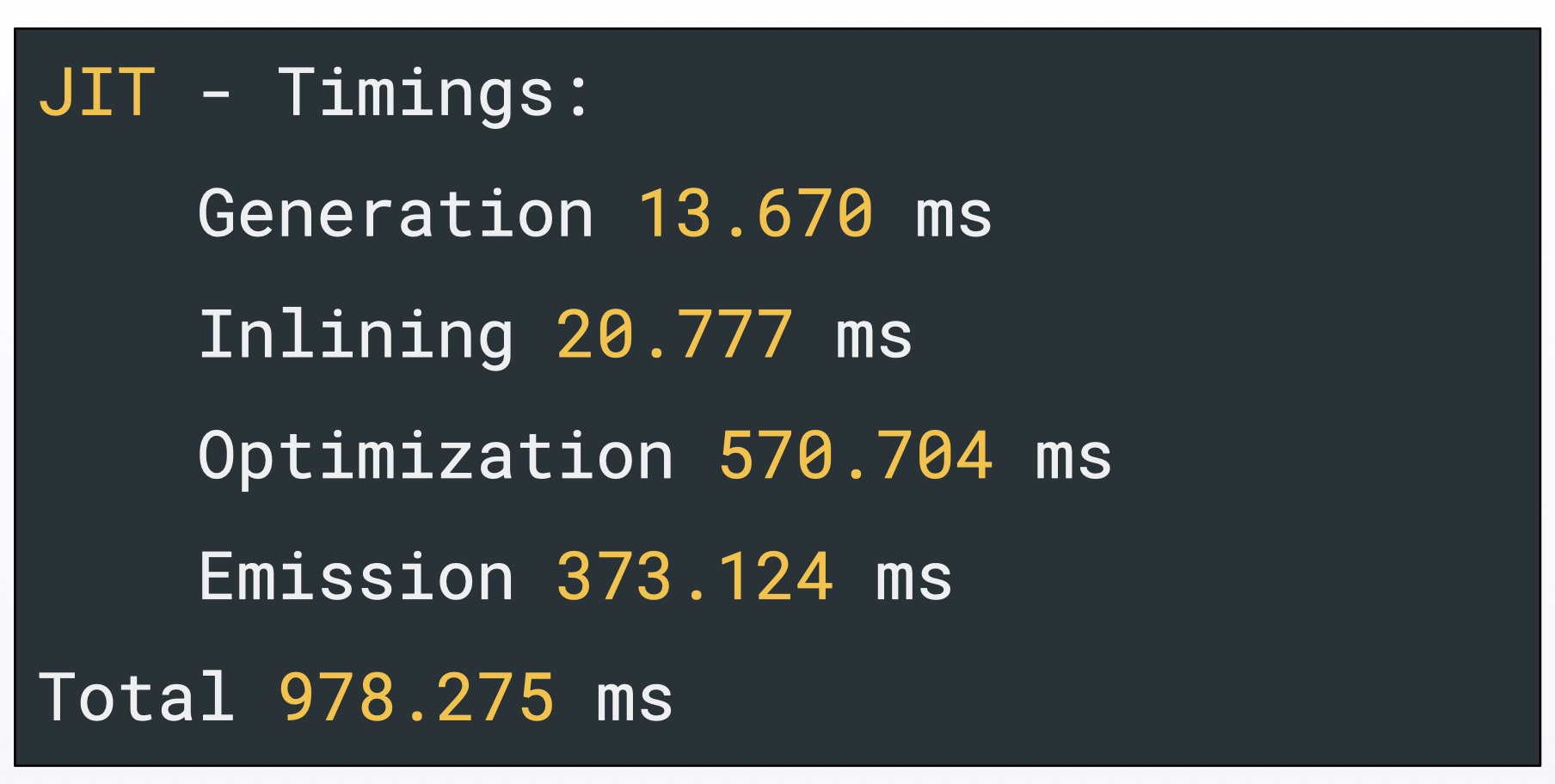
Using PostGreSQL’s `pg_stat_statements`, we were able to determine that our stored procedure `create_rollup` was slower on HyperScale than on Citus. In fact, it had a mean execution time that was two times slower than the Citus one. But why?
We had to dig in deeper, using a query plan. There, we found out that HyperScale was triggering the JIT, whereas Citus didn’t.
For those who don’t know it, JIT stands for “Just in time compilation”. In short, its role is to optimize specific queries at runtime. In our case, JIT was constantly being executed – even when the queries were optimized! This considerably slowed down the execution for this specific query.
The query plan also gave us a cause for the unnecessary trigger: we realized that JIT was not respecting a configuration option we had set. To be more specific, we disabled nested loops.
ALTER ROLE citus SET enable_nestloop = off;
SELECT run_command_on_workers('ALTER ROLE citus SET enable_nestloop = off')
Indeed, nested loops had a counterproductive performance impact on our Citus setup for our insert queries. However, as stated in the documentation, nested loops can never be completely disabled. When looking at the query plans, we saw that the JIT did use some.
Our solution was to disable the JIT entirely:
ALTER ROLE citus SET jit = off;
SELECT run_command_on_workers('ALTER ROLE citus SET jit = off');
We then confirmed it resolved our issue: after disabling the JIT on the HyperScale instance, both systems ran with the same performance and consumed the same amount of resources.
An update failure
However… slow queries wasn’t our only problem. We received this surprising error message in our logs:
That “duplicate key” error was quite surprising for us as our system was designed to only have unique keys. We realized that somehow our index had become corrupt, but as before we didn’t know why, and so we had to dig in.
This time, we found the answer by searching online for people encountering a similar issue. It turned out that the operating system’s `libc` was responsible for that error.
The C standard library or libc is the standard library for the C programming language, as specified in the ISO C standard. This library is used by almost all programs, including PostgreSQL. Postgres relies on the libc to compute the UTF-8 COLLATION used by indices. But unfortunately, the `libc` version was different on Azure, leading to this erroneous behavior.
As we learned from this blog post: Beware of the libc! Identical Citus and PostgreSQL versions don’t mean identical behavior, due to the different `libc`.
We crafted a recovery procedure in case that happened during the migration: a simple reindex on the table if the error occurred. As always – it’s better to know that kind of manipulation in advance.
As a final warning regarding this issue, the latter isn’t migration specific. For example, it could happen on your production database if your provider or your infrastructure team upgrades the operating system or the `libc` on the machine where your Postgres is running.
Migration: replicating & replacing
Now that we’ve tested all of the pieces, it’s important to explain how we went from one system that had been working fine for five years to another system that needed run in exactly the same way on day one.
Replicating
The replication involved:
Running the copying procedures to switch the large data from one system to the other
Testing the pieces (already discussed above)
Performing simulation tests on the whole process
Testing in production
Switching the pipeline
The goal here was to duplicate the Citus database on the HyperScale one.
With the help of the Citus team at Microsoft, we created a HyperScale DB from the existing Citus cloud backups. At that point, we had a fully replicated HyperScale DB in Azure.
On our side, once the DB was replicated, we “just” wired the duplicated services to this new instance.
It was that “simple”. Thanks to our testing, the redirected pipeline worked seamlessly with the new infra.
Simulating production
We already discussed how we tested each piece of the pipeline. For the last tests, we ran the whole process on our test server, to ensure that we had the same data and performance in both systems.
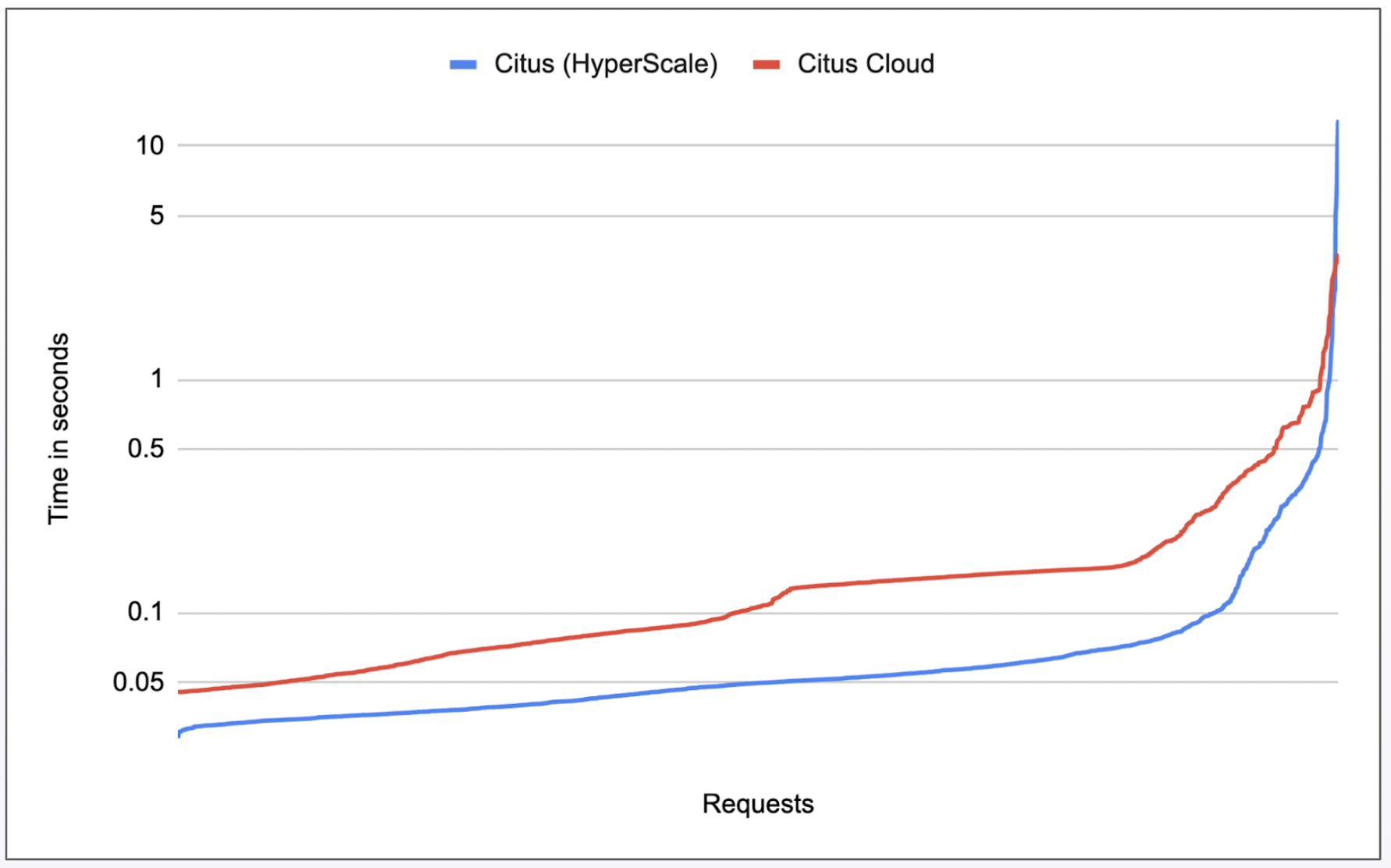
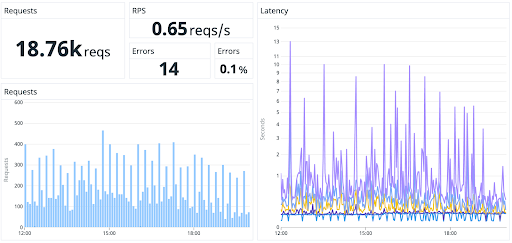
We tested by simulating the same conditions and running our most popular requests. We logged the 1000 longest API calls our current instance received over a given time frame. We then replayed those on the new instance. As you can see in this graph, we had results that were similar enough for us to feel safe testing further:
As for the overall user experience, we can see the reads performed at the same speeds in both old and new:
Testing in production
To be absolutely sure that we were ready, we did something terrible: we tested in production. While, in general, this is something we avoid as much as possible, it felt like the right option in this case, as it allowed us to test part of our migration playbook.
The way it worked was simple:
As before, the Citus team created a HyperScale follower of the Citus Cloud instance. Contrary to our write testing, here we waited for the instance to be completely caught up with the live instance.
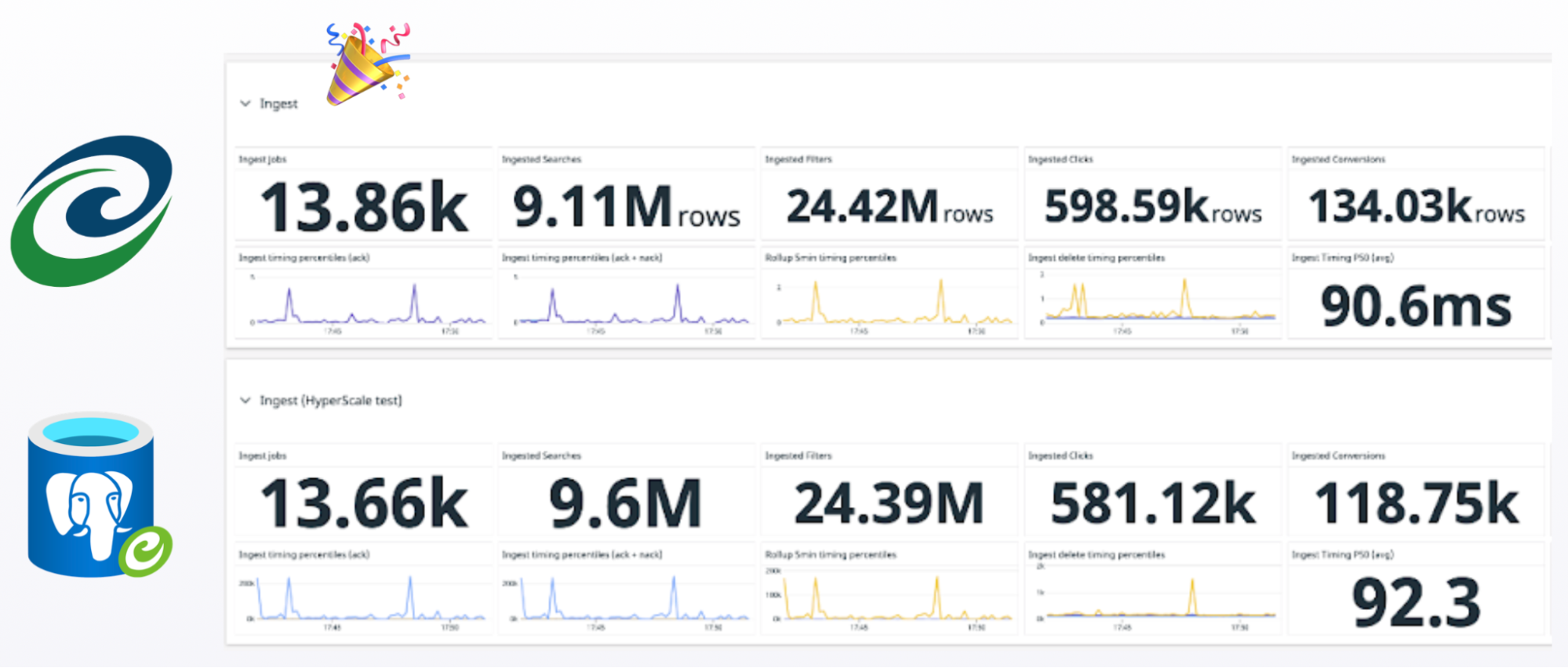
We then promoted the HyperScale instance to be autonomous. At this stage, the Azure data wouldn’t change anymore on this new instance. Our customers are mostly looking at historical data over some days. So the functionality wouldn’t change. Serving stale data for a small amount of time on our analytics pipeline is something we can afford which is why we simply switched our read traffic to target our HyperScale instance for one hour. During this time, we watched our monitoring metrics.
You can see the seamlessness of the migration on those graphs. Can you spot the switch-over? We could not.
Going live
Here are the steps we performed for the migration, as displayed in a GIF:
All in all, it went like a charm. The only serious hiccups took place in the pre-testing phases – where they should be. The whole migration process took 40 minutes. The following day, we ran the same migration on our US cluster, which went exactly the same way.
Takeaways
Overall, we learned the importance of creating an exhaustive migration playbook, challenging our biases, and monitoring for errors and performance regressions.
There are other takeaways:
If your system doesn’t require real-time, consider using eventual consistency. Being able to queue messages during the migration enabled us to perform the migration with zero-downtime.
Idempotence of our writes was a great ally to investigate performance issues. Instead of needing to recreate a testing environment that mimicked production, we could simply replay the same write queries in different scenarios.
Be prepared for the unexpected. Even by planning as much as we did, we still encountered a few hiccups along the way on migration day. For example, we saw some merging issues on GitHub with stacked pull requests. However, we knew we could correct this problem without changing anything in our playbook.
The final takeaway is about teamwork, more specifically, about working in pairs. In fact, that’s why there are two authors here: we performed this migration together, validating each other on nearly every step of the way. Pairing was a great way to challenge ideas and ensure we didn’t make any manual mistakes. As a result, we felt confident during the whole process. If you have to tackle a complex operational project in the future, we can only recommend that you pair up!