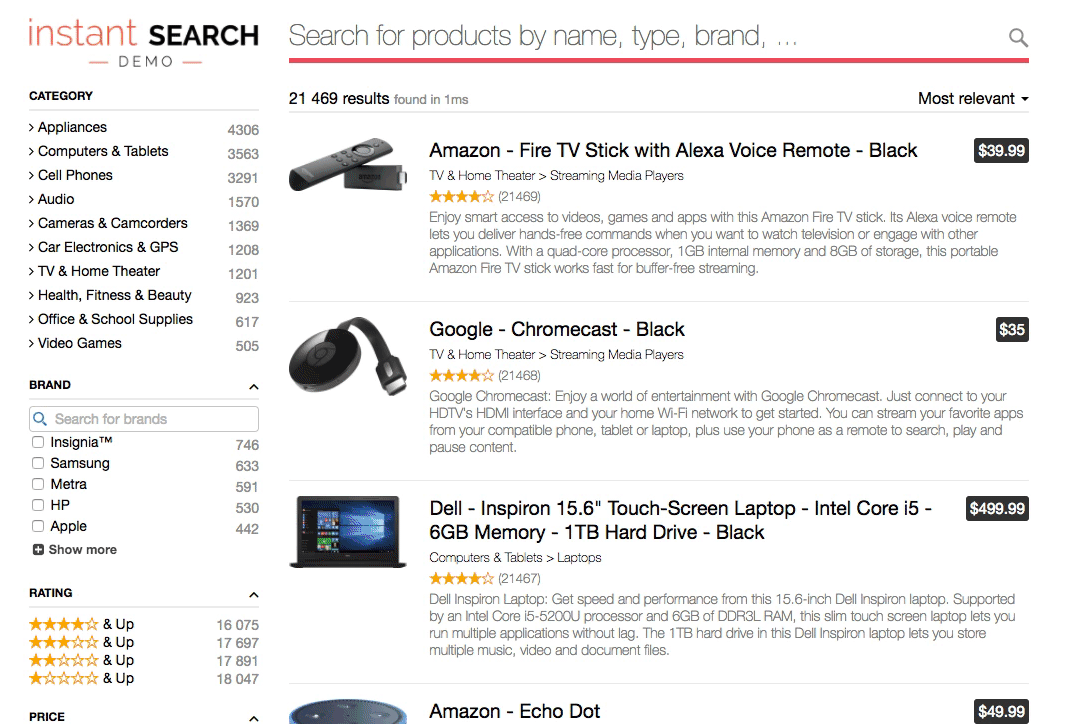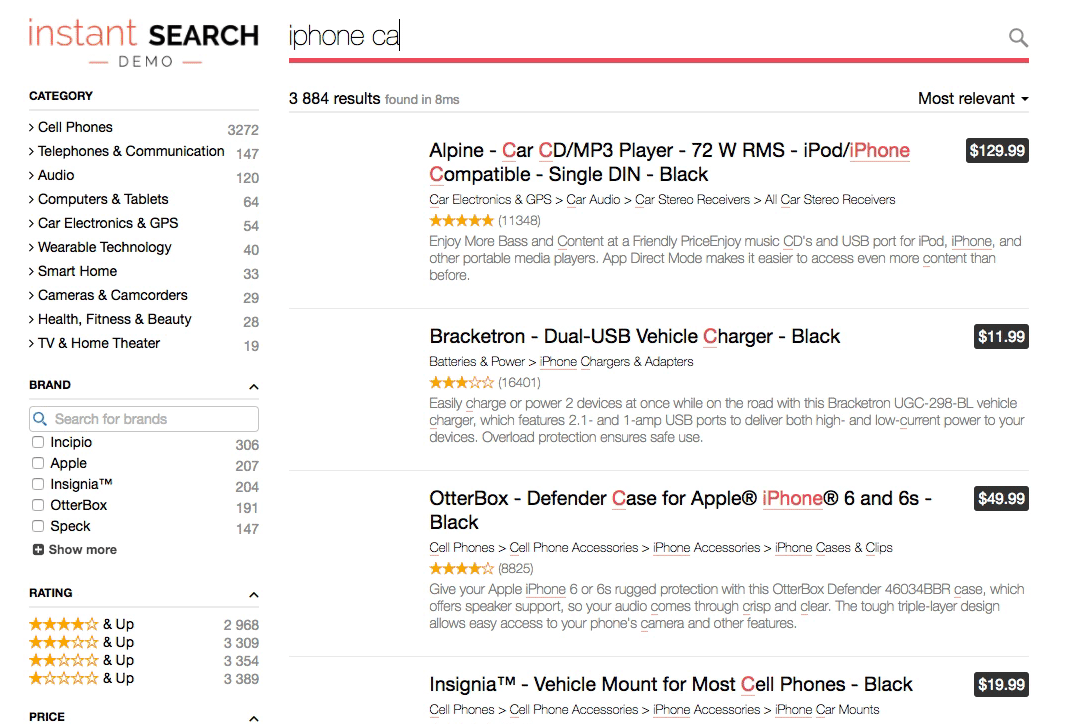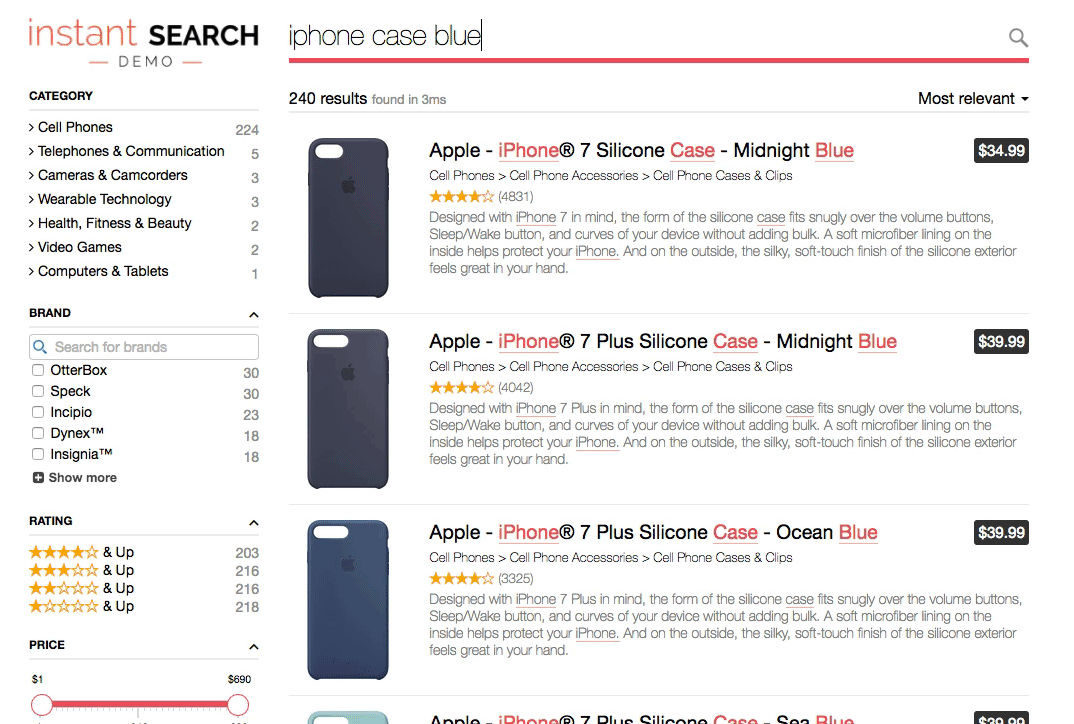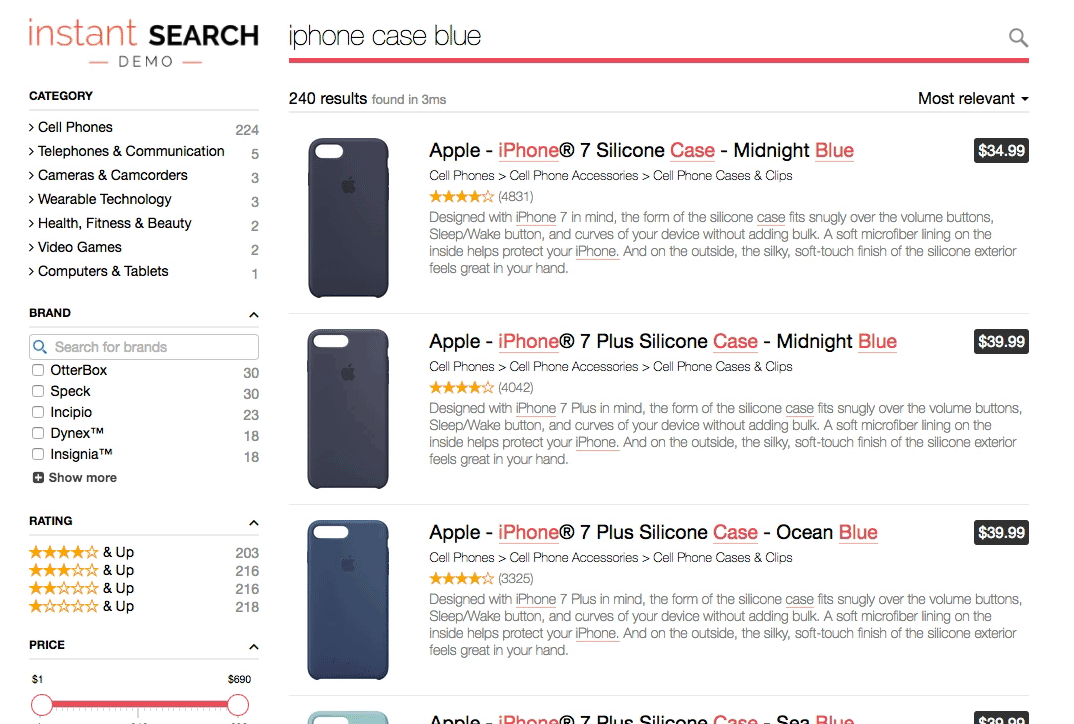
A relevant search returns the best results first. Google’s famous “I’m feeling lucky” button is a standing invitation for users to test their relevance by jumping through directly to the top hit. It’s a bold gesture when you consider that Google’s index contains trillions of documents, yet it works. The top result is often highly relevant and the user ends up right where they wanted.
“I’m feeling lucky.” – Average internet search user
If we want to understand what a consumer expects from their search, luck is a good place to start. If we want to understand what it takes to build that search, luck is a very bad place to start.
Great relevance is within reach for any search project, but it requires a careful understanding and application of complex techniques, several of which we’ll look at in this article. Whether you’re using Elasticsearch or Algolia, the goal should be to give your users a search they’ll love, a search so good you’d even consider putting an “I’m feeling lucky” button next to it!
Would I put an ‘I’m feeling lucky’ button next to my search box?
In Part 1 of this series, End-to-End Latency, we discussed the perfectly unreasonable search expectations of the average internet user, starting with speed. Global end-to-end response times must be lower than 100 milliseconds for search-as-you-type experiences to feel natural, with less than 50ms being ideal.
In this part of the series, Relevance Isn’t Luck, we’ll look first at consumer search behavior and why it challenges traditional approaches to relevance. Then we’ll look at how developers are adapting to these changes using the available tools, looking first at Elasticsearch and then Algolia.
Intuitive user experiences require smarter relevance
Consumer-quality search experiences are so streamlined that it’s hard to imagine what’s going on underneath, even for engineers. Yet many things that we take for granted as users have serious consequences for engineers trying to achieve good relevance.
Single input
In the early days of the web, most searches required you to separate your query into different boxes, one for each field you wanted to search in. Today, this is only the case for advanced searches, with the irony being that it’s actually simpler for the search engine to find and rank records when the query is split up into different fields.
Instant search
Search-as-you-type experiences have become the standard since Google Instant was introduced in 2010. Users love the immediate feedback and responsiveness of instant experiences. Product designers love instant search because it’s an efficient way for users to discover the content on their site.
Instant search introduces a brand new set of relevance challenges. The search engine can’t wait for a full word to be typed, it has to find and rank matches using only the first few letters.
Instant search vs. instant suggest
Not all instant searches are created the same. A variation called instant suggest is a multi-step process. Each new keystroke produces suggestions for keywords but not actual search results. Search results can only be reached by clicking on a suggestion or hitting the enter key.
Instant search produces real search results with every keystroke, no clicks or enter keys required. The user benefits from a streamlined experience and the development team has less moving parts to tune and maintain. But as we’ll see later, achieving the necessary speed and relevance is much harder for instant search than instant suggest.
Forgiving mistakes
On-the-go users misspell, omit and juxtapose words, and frequently get distracted and stop typing mid-sentence. Yet, when they gaze back down at their screen, they still expect to see the contact, movie or product they were searching for. This requires search engines to be much more forgiving than they were originally designed to be.
Mobile keyboards make forgiveness a must-have for two reasons: it’s easier to make mistakes and it takes longer to correct them. To make the search engine more forgiving, we’ll need to apply a variety of text and language processing techniques, designed to handle everything from typos to languages like Dutch and German that dontalwayshavespacesbetweenwords.
Promoting Results
Thousands of pages on the internet can tell you how to treat the common cold. How do you know which one to trust? Text-based signals aren’t enough—whether the page mentions the word cold 5 times or 50 times makes it no more or less trustworthy. To solve this problem for web search, Google created the PageRank algorithm which determines a page’s importance based on how many other pages link to it (and what those pages’ rankings are).
Most search engines, including Elasticsearch and Algolia, provide a way to promote results based on signals that aren’t related to the text itself. High-level attributes like trustworthiness, popularity, and affordability are commonly distilled down to a set of numbers, which are then used to sort records.
A particularly challenging part of relevance design is combining text-based relevance with strategies for promotion. The text represents the user’s intent while the promotion represents yours. These have to be considered in the right order.
For a great search UX, what the user is looking for must come before what you want them to find.
Relevance is a journey, not a destination
Relevance can be broken down into requirements, design, implementation, testing and maintenance phases. Now that we know what some of the requirements are, let’s jump into design and implementation, first with Elasticsearch and then with Algolia.
About Elasticsearch
If you’re not familiar with Elasticsearch, you can think of it as a set of tools for building a broad range of search and analytics applications. At the core of Elasticsearch is Lucene, a widely-used open source search engine first released in 1999. Part of Lucene’s wide applicability lives in its ability to apply very different similarity models to calculate relevance, including Okapi BM25 and TF-IDF, the new and former defaults used by Elasticsearch. In this sense, Lucene is a swiss-army knife, not a machete.
“Regardless of how easy Elasticsearch has made it, Lucene-based search is a framework, not a solution.” —Doug Turnbull, author of Relevant Search, June 2016
The job of a relevance engineer is to choose tools from the framework for the application in question. For consumer-grade search, tools are needed to handle:
Multi-field matching – Testing each query word against each searchable field
Prefix matching – Matching word parts for as-you-type search
Promotion of records based on non-textual signals like price or popularity
A predictable, debuggable way to combine and rank all of these signals
As we proceed, we must keep an eye on how each new layer impacts the relevance and the performance of the search as a whole. Like with most things in software, getting each component to work is easy. The hard part is making them all work together.
Poor applicability
There are a few features of Elasticsearch that should be ruled out early on, even if they look promising at first glance. This isn’t because they’re bad features, but because they’re not going to be powerful or fast enough for what we want to achieve.
Fuzzy queries allow forgiveness for typos and omissions, but for search-as-you-type they are simply too slow. Strategies to speed them up, like increasing prefix_length or reducing max_expansions, will cause other problems. In the case of setting prefix_length to 3 or more, we lose the ability to correct typos in the first 3 characters of the word.
There are also relevance concerns. There is no straightforward way to rank exact matches above fuzzy matches – the match query gives all fuzzy matches a constant score of 1, regardless of how inexact the query was. This has the consequence of making some records unreachable, even by exact queries, when typo-free variants are scored higher for other reasons. Fuzzy matching doesn’t work with phrase matching, and it also can’t be used with cross_fields in multi_match queries, which prevents us from specifying field-specific boosts.
Prefix queries allow you to match the first letters of a word but don’t handle phrases, where at least one full word has already been typed. match_phrase only works with whole words. match_phrase_prefix does work with prefixes but on the last world only, and it fails to find matches when the prefix is short (1-2 letters) and the index is large. For this reason, Elasticsearch advises to avoid it.
If the fields you’re searching tend to be short—names, titles, descriptions, sentences or short paragraphs—you probably want to turn off TF-IDF/BM25 altogether. Term frequency (TF) won’t be very helpful, as several occurrences of the same word in a short span isn’t usually a meaningful relevance signal. Inverse-document frequency (IDF) can unfairly penalize high-signal terms simply because they’re popular, like “Plato” will be in a search for philosophy book titles. You can read a very detailed explanation of this phenomenon from Doug Turnbull and the really sharp team at OpenSource Connections called Title Search: when relevancy is only skin deep.
There’s one other general advantage with not using IDF, which is that the relevance of a single document is self-contained. A new influx of documents with previously unencountered proportions of keywords can’t cause a relevance regression in the documents that were already present.
Higher applicability
While the previous Elasticsearch concepts might not prove that useful in the end for consumer-grade relevance, the next few can add more value, provided that we understand their limitations.
This important configuration knob lets a query return results even if some query words aren’t in the record. For example, if the user searches for “my quick brown fox”, the query can return a record that only contains “fox” but neither of the other 2 terms, if the minimum_should_match is 25% or lower. This scenario is especially important in instant search where not all query words are present until the end (or perhaps never at all).
A minimum_should_match value that is too high will exclude too many potentially good results, leading to zero-result scenarios more often. If the value was 50% in the example above, the “fox” result would not have been returned. A value that is too low will cause irrelevant results to appear. At 25%, the above query would also return results where “my” was the only word that matched. Finding the right value for this parameter is important, and requires you to understand both your data and the way that your users are searching.
The Completion Suggester can be used to create an instant suggest experience, as described above. It cannot be used to create a full-record instant search experience, as suggesters are limited to searching in only one field. Still, instant suggest has advantages that make it a popular choice, namely that it’s fast. Suggesters have a completely different in-memory execution path which helps make them fast enough for as-you-type search.
On the relevance side, suggesters have weighting and can do fuzzy matching. On the other hand, clients have to de-duplicate data and advanced features like filtering and faceting can’t be used. Read more about the pros and cons here: Quick and Dirty Autocomplete with Elasticsearch Completion Suggest.
n-grams
One of the most versatile tools in the Elasticsearch toolbox is n-grams, where words are broken down and indexed as smaller groups of letters. The “brown” would be indexed with the tokens [“b”, “br”, “bro”, “brow”, “brown”, “r”, “ro”, “row”, “rown”, “o”, “ow”, “own”, “w”, “wn” and “n”].
A subset of n-grams called edge n-grams are a better choice for instant search, because all tokens start from the beginning of the word and because there will less tokens overall, improving the speed of the search. The edge n-grams for “brown” are just [“b”, “br”, “bro”, “brow”, “brown”]. With n-grams a query for “row” would match “brown”. This is called infix matching and it usually does more harm than good for relevance—another good bad example is a search for “nathan” matching “jonathan”. Edge n-grams only afford prefix matching, so “row” will only match “rower” or “rowboat”, not “arrow”.
Similar to the limitation that fuzzy matching has with ranking exact above inexact matches, n-grams don’t come with a way to rank full word matches higher than partial ones. N-grams don’t store information about whether the token represents a full word. Without that, we can’t guarantee that “motor” will be ranked above “motorbike” for the query “motor”.
Shingles
Another limitation of n-grams is not being able to use them for phrase matching, where we want to giving ranking preference to records where the terms match in the right order. A name search for “anne marie” should rank results for “marie anne” after “anne marie”. This is very important when there are many people named “marie anne”, because the user may never be able to reach the “anne marie” record they were looking for otherwise. N-grams don’t store the position or order of tokens, so it’s impossible to satisfy this ranking requirement with n-grams alone.
Shingles are often used instead of (or in concert with) n-grams because they do retain information about word proximities. Shingles are similar to n-grams in that they represent tokens, but instead of breaking up words into letters, they break up phrases into words. The shingled tokens of “quick brown fox” are [“quick brown”, “brown fox”].
For search-as-you-type relevance, shingles will have to be used alongside n-grams because shingles won’t help us do prefix matching. An Elasticsearch implementation using both techniques is referred to here by DogDogFish. However, the increase in index size and amount of scanning at query time make the combination of shingles and ngrams almost certainly too slow for full instant search. Presumably for that reason, and also to handle typos, the DogDogFish team ended up with a mix of instant suggest for keywords, instant suggest for spelling correction, followed by keyword search to find results.
“If there is a particular search found to yield bad results, it can be easy to optimise towards improving and fixing that search, but then other searches end up suffering as a result.”—DogDogFish
Delivering relevance with Algolia
Unlike Elasticsearch, Algolia is not a swiss-army knife for implementing a myriad of front-end and back-end search use cases. But nor is it a single blade capable of only one kind of search—the API is highly customizable and individual search implementations vary widely by data, user interface and audience.
A good way to think about Algolia is a set of wrenches, each a different shape or size, purpose-built to tighten a specific nut or bolt of a fully instant consumer-grade search.
Multi-field
Algolia is designed to index structured data, not large blocks of text, so searching in multiple fields of a record is the default behavior. The list of fields to be searched is specified in the searchableAttributes property of the index. It can be changed at any time in the Algolia Dashboard or API.
The list of searchable attributes is ordered, with the most important attributes being first. The ordering is considered at query time by the ranking formula, which is the foundation of how Algolia computes relevance. Algolia’s ranking formula contains a handful of different criteria, each meant to handle a specific relevance need. For multi-field-aware ranking, matches in some fields need to count more than others. This is done by the formula’s attribute criteria.
Unlike Elasticsearch, there are no term or match queries that operate only against single fields; conceptually everything is multi_match. Likewise, there are no operators like bool or dis_max to combine relevance signals from multiple fields— this is handled by the ranking formula itself.
The ranking formula, including the attribute criteria, doesn’t require developers to specify how much more important one criteria (or one attribute) is than another, only that it is simply more important. In contrast to Lucene-style boosting, no coefficients need to be provided.
Algolia uses a tie-breaking algorithm, not the computation of a score, to rank documents. The algorithm considers each criteria, one after the other, to successively sort the result set into parts. Read more here about the tie-breaking algorithm and ranking criteria.
Prefix matching
For the query “sun”, exact matches like “sun” need to be ranked above partial matches like “sunflower”. Otherwise, records about the sun will be impossible to reach if there are many records about sunflowers—there is no way for the user to be more precise than “sun” when they are looking for records about the sun.
Showing a sunflower to a consumer when they wanted the sun will cause a ton of frustration, so much that we want to guarantee it won’t happen. The exact criteria in the Algolia ranking formula makes sure that full-word matches count more than partial-word matches. The criteria not only can rank one prefix against one word, but it also combinations of multiple full words and multiple prefixes.
Forgiveness
The typo criteria in the ranking formula guarantees that exact matches for query words count more than matches where this a mistake. The reasoning is because sometimes a typo is not actually a typo, it just depends on what the underlying data is.
Take a query for “jon”. This is either an exact match for “Jon” or a 1-letter omission typo for “John” or “Joan”. The search engine needs to guarantee that people named “Jon” appear before “John”, while still showing “John” and “Joan” afterwards. The “jon” query is simultaneously a typo for some records and not a typo for others. The records for which it is not a typo need to come first.
Both Algolia and Elasticsearch use the Damerau–Levenshtein distance algorithm for computing typos based on word distance. Spelling mistakes, however, are just a small fraction of dealing with the reality that it is a human in front of the search box, and that humans speak different languages and phrase things in different ways.
In Elasticsearch, search teams add analyzers to the indexing path or the query path to handle the quirks of language, and there are quite a few to choose from. With Algolia, queries are put through a two-step tokenization and alternative-word matching process that handles many common cases for a variety of different languages. For a deep dive, check out the Query Processing edition of the Inside the Engine series, but here are a few examples:
Abbreviations and apostrophes: In French, “l’aigle” (the eagle) needs to be indexed as aigle not laigle – simply removing the apostrophe will produce very bad relevance. But if indexing English, “don’t” should be just one token “dont”.
Agglutinative languages: Some languages like Japanese, Chinese and Korean don’t have word separators. A statistical approach is required to break words into tokens. Here, typo tolerance is not based on word distance but on synonyms between ideograms, so that you can search for simplified Chinese using traditional Chinese and vice versa.
Prefix correction: Beyond Damerau–Levenshtein, Algolia keeps a dictionary of words that can be used to correct prefixes. If the user inputs “jhon” the prefix will be corrected to “john” automatically, since “john” will have been in the dictionary. This situation is often overlooked but is essential to a good instant search experience. Mistakes are very common in the first few characters of a search, as we all know from using our mobile devices.
Typosquatting
When you mistype a domain name and end up on an ugly “Domain For Sale” page, you’ve been a victim of typosquatting. Domains aren’t the only place typosquatting happens. It’s also common on social networks, where it takes advantage of the search’s preference for exact matches. @BarakObama on Twitter, who is not @BarackObama, has 16.3k followers. To prevent typosquatters from getting to the top of the search results, we need to do something that is the opposite of what we usually recommend – we need to consider another signal to be more important than the text. Because the elements of Algolia’s ranking formula can be reordered, this is easy. The recommended solution is to add an isPopular attribute to the data, set it to true for the top ~1% of accounts, and put it above the typo criteria in the ranking formula.
Promotion
Multi-field matching, prefix matching, forgiving mistakes and understanding the intricacies of language all fall under an umbrella that Algolia calls textual relevance. Textual relevance is all about what the user wants to find.
Business relevance is about what you want the user to find. When your index contains textually identical people, products or items, Algolia gives you the custom ranking to push the most important records to the top. A custom ranking might be driven by business metrics, popularity metrics, or attributes intrinsic to the record, like price. As with textual relevance, your Algolia custom ranking can take into account many signals, while still giving you a guarantee about the order in which they matter.
By default, the ranking formula applies textual criteria first and only then the custom ranking. This provides a guarantee that promotional signals will not override the textual quality of the match, which is one of the most common situations that lead to bad relevance and a bad user experience.
Conclusion
In Part 1 of this series, we looked at how instant search forces us to think about latency in a new way. The same is true for relevance. We can no longer search by full words only nor assume the query has made it accurately from the user’s head into the search box.
The path to great relevance looks different whether you are using Elasticsearch or Algolia. Because relevance and user experience are inextricably linked, the type of user experience you will end up providing may also be different. Recent Elasticsearch additions like the Completion Suggester are designed to help developers build an instant suggest experience that is fast enough for as-you-type search, with a tradeoff of some functionality. For full instant search, Elasticsearch users should expect to make trade-offs between speed, relevance and how predictive or forgiving the user experience is.
Algolia is built from the ground-up for full instant search. Tradeoffs center around different ways to model data and finding the most cost-effective ways to integrate, but not around speed, relevance or user experience.
Read other parts of the Comparing Algolia and Elasticsearch for Consumer-Grade Search series: