Simplicity is critical for search engines, but building one that enables that simplicity is complex.
Over the last 20+ years, most on-site search solutions have enabled matching a customer’s query to a search index. Then starts the job of tuning the engine. That’s because search engines can’t understand the searchers’ intentions very well. Is someone who searches for “what is rust” looking for the corrosion process, a computer programming language, or something else? For years, anyone who has had to optimize the search engine has used either manual rules, synonyms, keyword stuffing, or some other basic AI to “patch” the matching to achieve understanding.
The evolution of search: from keyword matching to AI.
Building end-to-end AI was possible, but impractical to operate at scale due to cost and performance challenges. This just changed with Algolia NeuralSearch, which includes native end-to-end AI processing. This blog will cover what end-to-end AI means and why it matters.
Why end-to-end AI matters
It is likely a whole topic in itself, but let us align on the real need on why end-to-end AI matters before we go further into what it is. Algolia has 17000+ customers, and we have helped them achieve double digit conversion uplifts over the years. Even with the most optimized engines, when we look at the typical search profile, it is clear that the long tail is untapped. Historical data suggests that most companies will optimize their most popular queries, however, 50-70% of revenue is left on the table due to unoptimized long-tail. Theoretically, if one had unlimited time and resources, one could manually optimize it all — but that’s beyond human capacity.
For example, let’s look at the search profile of two large retailers in the UK and the US, respectively, a very good representation of the majority of online businesses. Can anyone manually handle this kind of long tail? Can this be optimized by patching AI on the top and bottom of the core engine? ….. NO!! That’s just impractical.
There is a staggering number of product variations typically found on ecommerce sites, which makes it impractical — not to mention nearly impossible — to optimize every term for long tail queries.
That’s where the need to take the machine’s help arises. Machine learning algorithms can optimize all 100% of search catalogs. Until now, that wasn’t easily possible, but with the maturity of AI algorithms, richer data, and more powerful cloud computing, we can now apply AI across any size catalog. Deploying AI end to end, right from the point of a consumer typing the query till the time results are served, is the solution to this challenge.
So why is end-to-end AI needed? Until now, most AI solutions have only focused on solving for discrete parts of the search query. For example, query processing — the first step of a search query result — or ranking, which typically comes last.
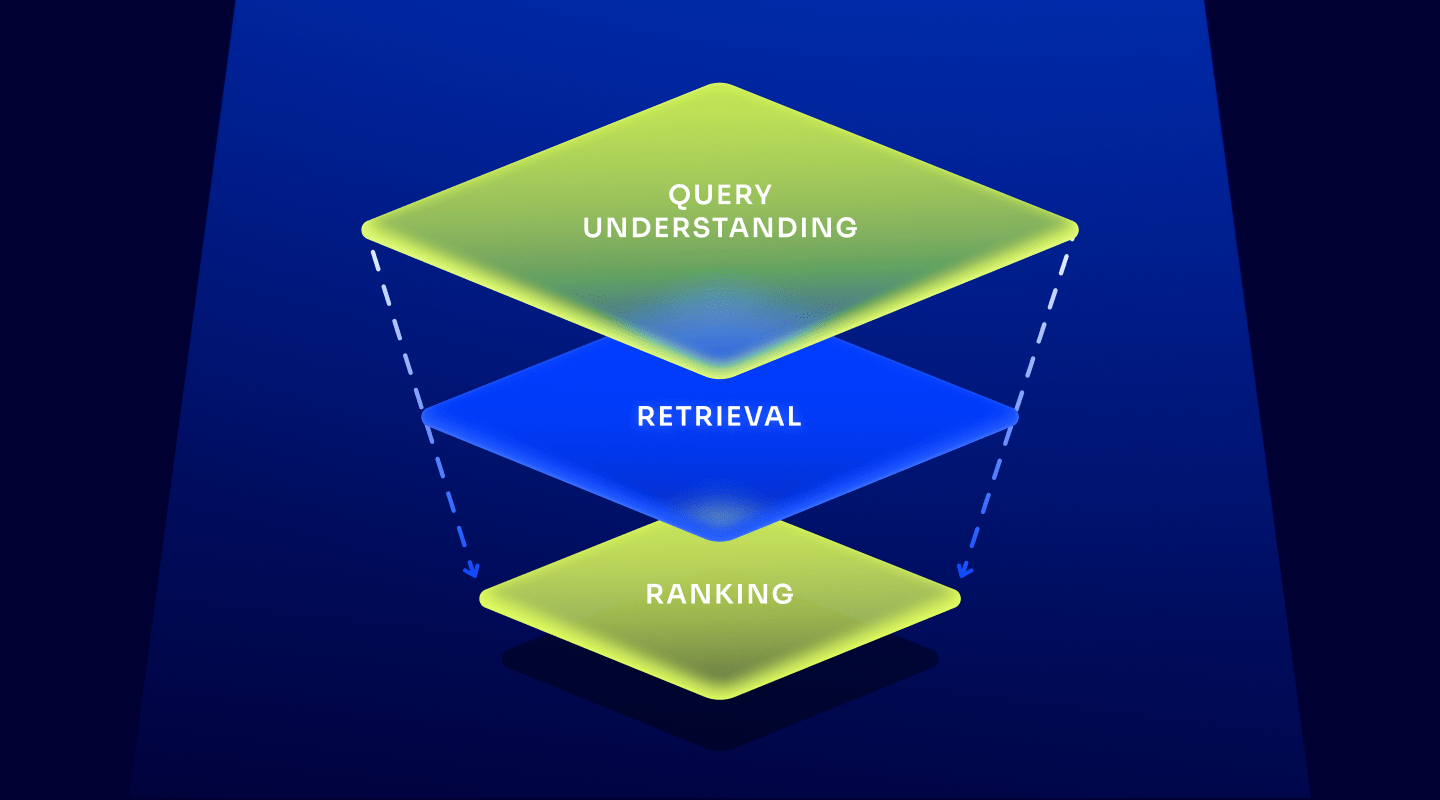
End-to-end AI search includes AI-powered query understanding, retrieval, and ranking.
The missing link was using AI for retrieval. Retrieval is when the search engine attempts to find the most relevant information. Arguably, AI has the biggest impact in the quality of results during retrieval. With the maturity of AI machine learning today, it’s something that can finally be tackled.
We’ll explain further how each stage of AI works to deliver better results.
End to End AI
Algolia NeuralSearch sends each query through three phases to deliver the best results. We call it end-to-end AI search to differentiate from competitive solutions that may only offer AI at specific phases of processing. These phases include: query understanding, retrieval, and ranking. Each of these discrete capabilities provide value to the final results.
Query processing
Query processing consists of natural language processing (NLP) and natural language understanding (NLU). NLP is involved with parsing and processing the language in a search bar to prepare a query for execution. The process could be as simple as comparing the query exactly as written to the content in the index. Classic keyword search is actually more advanced than that, because it involves tokenizing and normalizing the query into smaller pieces – i.e., words and keywords. This process can be easy (where the words are separated by spaces) or more complex (like some Asian languages, that do not use spaces, so the machine needs to recognize the words).
NLU is focused more on determining user intent. It uses machine learning intent classification, semantics, synonyms, and ontology expansion to understand words and phrases. This step improves the interpretation and understanding of the query. For example, two queries can use the same terms to mean very different things:
Dishwasher-safe metal bottle
Fire safe metal box
The first case is an example of using the term “safe” as an adjective for a water bottle, whereas the second is a noun — a metal safe for storing valuables. In these particular examples, NLP tokenization is used to help break down each phrase, and NLU helps interpret the meaning of each query. This is true for both text and voice search, but voice search can get trickier with homophones like “pear”, “pair”, and “pare”, for example.
Retrieval
Better information retrieval can improve both search precision (result accuracy) and recall (result completeness across your entire index). It’s hard to strike a balance between precision and recall; improving one can have the inverse effect on the other. Keyword search engines tend to provide better results for head terms, whereas AI vector search works well for less popular long tail queries. You need to solve for both, which is sometimes called hybrid search.
Keyword search typically relies on statistical matching using BM25 or TF-IDF and related techniques for ranking results based on the query terms that appear in each document. For example, TF-IDF looks at the inverse frequency of a word in a document (IDF) versus the term frequency of a word (TF) to determine its importance. Stop words include things like “the” “and” “or” — terms that that show up frequently everywhere compared to words like “toothbrush” or “water” that show up less frequently — that is, they are more uncommon and likely more informative about the content. Term frequency can be used as a proxy for how important, or relevant, the document is. Most of the models required to build keyword search are readily available. Many companies still use Lucene, the venerable Apache project that spawned both Elasticsearch and Solr.
Semantic search requires a different approach, however. It is typically powered using large language models (LLMs) to create vector embeddings. Vectors are mathematical representations of words, images, videos, or just about any type of object you might want to compare. Machine learning models determine semantic relationships between objects in an index. Vectors can have hundreds, or even thousands of dimensions, which can be used to determine similarity. It’s hard to visualize that many dimensions, so most of the time we use three-dimensional representations like the image shown below.
Vector search can connect relationships between words, and similar vectors are clustered together. Vectors can be combined (or subtracted) to create new meaning and understand relationships; the classic example is “King -man = queen”.
Image via Medium showing vector space dimensions. Similarity is often measured using Euclidean distance or cosine similarity.
Vectors are huge, typically require specialized GPU-powered databases, and are expensive to scale while also being performant. Techniques such as HNSW (Hierarchical Navigable Small World), IVF (Inverted File), or PQ (Product Quantization, a technique to reduce the number of dimensions of a vector) are some of the most popular Approximate Nearest Neighbor (ANN) methods to find similarity between vectors. Each technique focuses on improving a particular performance property, such as memory reduction with PQ or fast but accurate search times with HNSW and IVF. It is common practice to mix several components to produce a ‘composite’ index to achieve optimal performance for a given use case.
Even with most approximate nearest neighbor (ANN) techniques, there’s no easy way to design a vector-based search algorithm that’s practical for most production applications. For example:
Insert, update, and delete functions can challenge graph based structures like HNSW, which make deletion very complex.
Sharding vector indexes is very expensive. HNSW performance drops off non-linearly with more shards.
Combining keyword and vector results is really hard because the relevance computation in each system is completely different, so we can’t compare them easily, which is why you see many people bolting a vector ANN index on top of a keyword engine. Essentially, vectors are only being used as a “fall back” option to prop up results when keywords fail.
At Algolia, we pioneered a new technique called neural hashing. Essentially, we use neural networks to compress vectors into tiny binary files that still retain most of the information. The binary vector is much smaller and faster to calculate than standard vectors, which allows us to run vector and keyword search simultaneously and at scale on commodity CPUs. We then normalize and combine the results to provide a single measure of relevance in the same query.
These tradeoffs, plus the cost associated with scaling dense vector search, make building AI relevance outside the scope for many organizations.
Site and app search is just one application for vectors. It is worth mentioning here, that vectors can also be used to compare many different kinds of objects such as images, video, symbols, or even entire documents, and have many different real world use cases such as movie recommendation systems, facial recognition, fraud detection, and more.
Ranking
Product ranking can make a huge difference in search success. There is position bias in result ranking — the first three results get significantly more clicks than lower ranked ones. There is also a need to constantly re-rank results; results that rank high today may need to be buried tomorrow if something more relevant or popular becomes available.
If your retrieval is good (see above) ranking starts from a better position. Learning-to-rank (LTR) , sometimes also referred to as Machine Learned Ranking (MLR), is a type of machine learning that improves ranking and assists with precision. It includes supervised, unsupervised, and reinforcement learning. There are also variations like semi-supervised learning. Each of these solutions offers AI ranking capabilities to deliver improved results over more simpler statistical methods.
In recent years, learning-to-rank techniques such as reinforcement learning have become more popular because they reduce maintenance and iteration. Reinforcement learning uses events such as clicks, conversions, purchases, etc., to re-rank results from most to least popular. It can also do the opposite — bury results that aren’t performing well. The challenge for ranking is data. Reinforcement learning normally requires a lot of data to work, but newer models are coming out that enable better prediction with less data.
While the machine learning involved seems like maybe an easier challenge to tackle than relevance, it may not be. It took AirBnB a team of very talented data scientists and engineers two years to build an AI ranking solution!
Conclusion
In this article, we focused mainly on the AI bits and pieces for building a search solution. Of course, there are many, many other considerations — from features like optimizing search speed, ranking control, indexing, merchandising, and security, to infrastructure decisions such as reliability, build management, database management, and more.
We’re biased, of course. Algolia has built the world’s most advanced AI search engine, NeuralSearch, which is designed to accommodate just about any use case. We have recently announced pricing and availability, and are now offering a product that customers can deploy instantly for many different use cases.